Welcome to the 12th newsletter from the EU POP Centre of Excellence. For new requests, please see section “Apply for free help with Code Optimisation” at the bottom of this newsletter.
This issue includes:
- POP webinar – “Implementing I/O Best Practices to Improve System Performance with Ellexus” on Monday 9 September 2019 14:00 BST / 15:00 CEST;
- Installing and Managing HPC Software with Spack;
- Measuring OpenMP Serialisation in Hybrid MPI and OpenMP Codes in Scalasca;
- Parody_PDAF POP Assessment;
- CubeGUI and its Plugins;
- POP out and about – meet POP members face to face at the following events:
- UK RSE Conference, Birmingham, UK. 17 - 19 September 2019;
- CompBioMed Conference, London, UK. 25 - 27 September 2019;
- International CAE conference, Vicenza, Italy. 28 - 29 October 2019;
- Supercomputing Conference, Denver, US. 17 - 22 November 2019.
- Apply for free help with code optimisation;
- The POP Helpdesk.
For information on our services and past editions of the newsletter see the POP website.
POP webinar - Implementing I/O Best Practices to Improve System Performance with Ellexus
Rosemary Francis, founder and CEO of Ellexus
Monday, 9th September, 14:00 BST / 15:00 CEST
Bad I/O harms shared storage and limits performance significantly, problems that no amount of extra hardware or cloud spend can fix.
In this 30-minute live webinar, Rosemary will explain common I/O problems and best practices to implement easy performance wins. She will outline I/O profiling for improving application performance as well as I/O monitoring for improving HPC system performance through good application deployment. Understanding I/O patterns can give easy wins as often a simple fix can make the biggest difference but knowing where to look is crucial. Rosemary will demo I/O profiling tools from Ellexus that provide system telemetry and application performance metrics.
Click here for more information and to register.
Installing and Managing HPC Software with Spack
Manually installing software such as the POP tools on an HPC or other compute target can be a lengthy and complex process. Fortunately, there are now several package managers available designed especially for installation of HPC software. One such tool is Spack which allows both system administrators and regular users to quickly and easily manage their installed software, using already installed packages where they are available. Spack allows users to easily select different compiler and MPI library combinations, and this is particularly useful for profiling tools where the MPI library used by the profiling tool must match the MPI library used to build the application. In addition, some profiling tools require the compiler to match the compiler used to build the application. For more information read our blog post on Spack here.
Measuring OpenMP Serialisation in Hybrid MPI and OpenMP Codes in Scalasca
Hybrid MPI and OpenMP parallelisation is a popular way to increase the scalability of MPI codes. It reduces the number of MPI processes, thus reducing the amount of buffer memory required for data transfer and the size of the communicators. The OpenMP region is usually created per NUMA region or per compute node. The communication can be either done in the OpenMP serial regions, or within an OpenMP region and handled by the master thread. However, OpenMP serialisation can reduce the parallel scalability of hybrid codes and this article will explain how to measure this amount of serialisation to determine if this is a performance bottleneck.
Parody POP Assessment
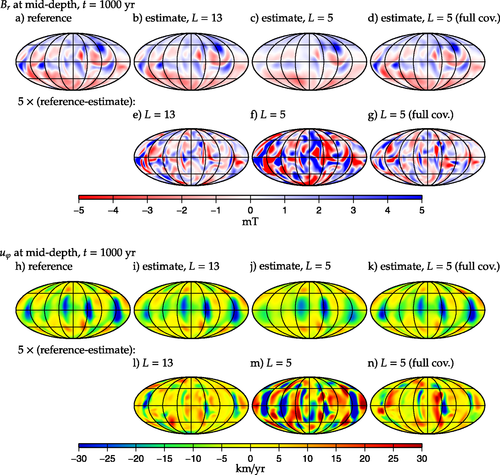 POP recently completed an exhaustive parallel performance assessment of the PARODY_PDAF code, one of the flagship applications of the European ChEESE Center of Excellence in pre-exascale and exascale solid earth modelling and simulation (https://cheese-coe.eu). PARODY_PDAF models incompressible magnetohydrodynamics in a spherical cavity to simulate convection-driven dynamos in planetary cores. It is written in Fortran using hybrid MPI and OpenMP parallelisation.
POP recently completed an exhaustive parallel performance assessment of the PARODY_PDAF code, one of the flagship applications of the European ChEESE Center of Excellence in pre-exascale and exascale solid earth modelling and simulation (https://cheese-coe.eu). PARODY_PDAF models incompressible magnetohydrodynamics in a spherical cavity to simulate convection-driven dynamos in planetary cores. It is written in Fortran using hybrid MPI and OpenMP parallelisation.
The PARODY_PDAF developers were delighted to have confirmed the excellent efficiency performance for pure MPI parallel execution, and were given valuable insight into the impact of file I/O and into issues in the hybrid MPI and OpenMP execution, which showed less than ideal scaling due to Amdahl's law. They said “Interacting with POP proved extremely useful in providing us with a set of rigorous metrics to evaluate the performance of our code and assessing what the next stages of development should be in view of being in a position to run efficiently on the next generation of supercomputers”. The assessment findings will be used to guide the next stage of the PARODY_PDAF code development.
CubeGUI and its Plugins
In the previous blog article POP tool descriptions: JSC performance tools, we gave a short overview of one of the JSC performance tools, the Scalasca Trace Analyser. Here we give a short introduction to Cube, another JSC performance tool in the Scalasca context with a particular focus on the CubeGUI.
POP out and about – meet POP members face to face at the following events
POP will be attending the following events. If you would like to meet a member of the POP team, please email pop-helpdesk@bsc.es and we will happily arrange a meeting with you.
UK RSE Conference, Birmingham, UK. 17 - 19 September 2019
The UK Research Software Engineering (RSE) conference will focus on software development for the research and academic community. This year they have increased the conference to 420 delegates – a third larger than previous years – and expanded from 2 to 3 days, with the third day purely for workshops. They have, as ever, a varied talks and workshop programme split across multiple streams.
CompBioMed Conference, London, UK. 25-27 September 2019
The CompBioMed conference will address all aspects of the rapidly burgeoning domain of computational biomedicine, from genome through organ to whole human and population levels, embracing data driven, mechanistic modelling and simulation, machine learning and combinations thereof. You can hear all about POP in one of the Friday sessions.
International CAE Conference, Vicenza, Italy. 28 - 29 October 2019
POP will make a return visit to this leading Computer Aided Engineering conference, now in its 35th year. We will have a stand in the research agorà, which provides major projects an opportunity to promote their activities and disseminate their results. Here, we will discuss the work of POP and provide live demos of the profiling software we use.
Supercomputing Conference, Denver, US. 17 - 22 November 2019
Established in 1988, the annual SC conference continues to grow steadily in size and impact each year. Approximately 5,000 people participate in the technical program, with about 11,000 people overall. You can meet our experts at the research exhibition booth of BSC (#1975), HLRS (#409), IT4I (#2219), JSC (#1563), or NAG (#932).
Apply for free help with code optimisation
We offer a range of free services designed to help EU organisations improve the performance of parallel software. If you are not getting the performance you need from parallel software or would like to review the performance of a parallel code, please apply for help via the short Service Request Form, or email us to discuss the service further and how it can be beneficial.
These services are funded by the European Union Horizon 2020 research and innovation programme so there is no direct cost to our users.
The POP Helpdesk
Past and present POP users are eligible to use our email helpdesk (pop-helpdesk@bsc.es). Please contact our team of experts for help analysing code changes, to discuss your next steps, and to ask questions about your parallel performance optimisation.
