[This blog article is a reissue of the NAG blog post "Not Only Fortran and MPI: POP's View of HPC Software in Europe" ]
At the recent Computing Insight UK conference in Manchester (12-13 December 2017), POP presented an overview of how we've seen people using and writing HPC software in Europe. We thought we'd summarise the talk here on our blog for those of you who couldn't make it to the event. As you'll see, there's more to the work POP has undertaken than just looking at Fortran code parallelised with MPI!
In just over 2 years of operation POP has undertaken over 150 investigations of codes drawn from a wide range of scientific domains. One of the first questions we ask our users is "Up to what number of cores are you satisfied with the performance of your code?". This information is useful to POP's performance analysts as we actively look to stress the codes we study in order to identify the areas that can be improved. Taken together the answers also give us some insight into how people are using HPC resources in Europe:
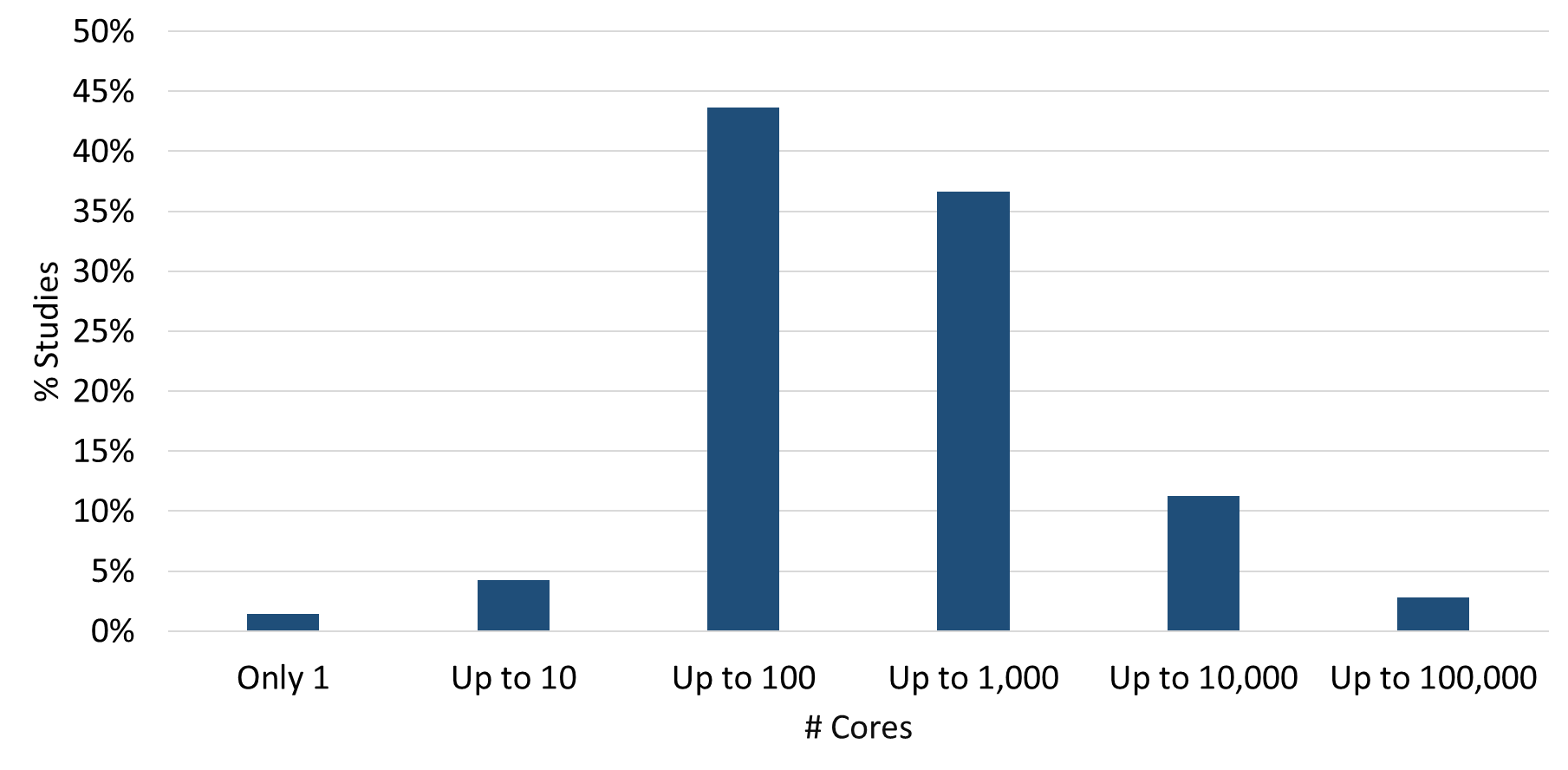
We see that the bulk (80%) of POP studies have looked at codes that run best on more than 10 but less than 1,000 cores.
Languages and Parallelism
As you might expect (particularly if you've read our previous blog post) Fortran codes dominate, with over half the studies (82 of 151) written in either pure Fortran or Fortran combined with C and/or C++. C++ seems more prevalent than C, but C is more likely than C++ to be combined with Fortran:
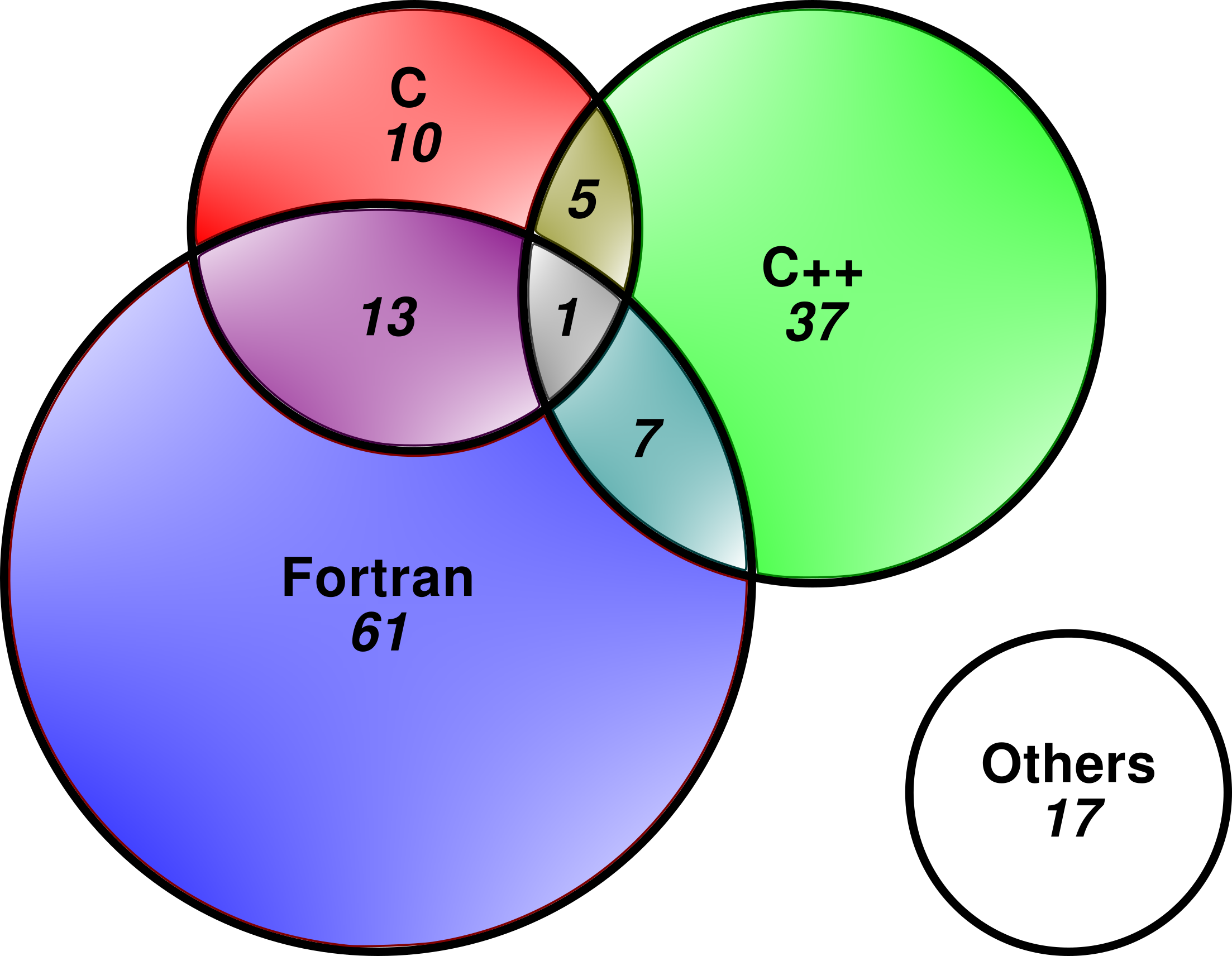
(The areas of the circles in the Venn diagram are proportional to the number of studies they contain). The "Others" category makes up about 10% (17 of 151) studies. Of these, 13 involved Python, either stand-alone (3) or in conjunction with one or more compiled language. The other "Others" were a combined C/Fortran/Octave code, a Java code, a Matlab code, and a Perl code. The fact that 10% of POP codes are written in languages other than C/C++/Fortran demonstrate that it's important to have tools and methodologies capable of handling a wide range of languages and not just the usual suspects.
We have also looked at the types of parallelism used by the codes we have studied. We see that MPI is the most common form of parallelisation, with nearly 80% (119 of 151) codes using either pure MPI or MPI+OpenMP. Over a third of codes POP has looked at are hybrid (MPI+OpenMP).
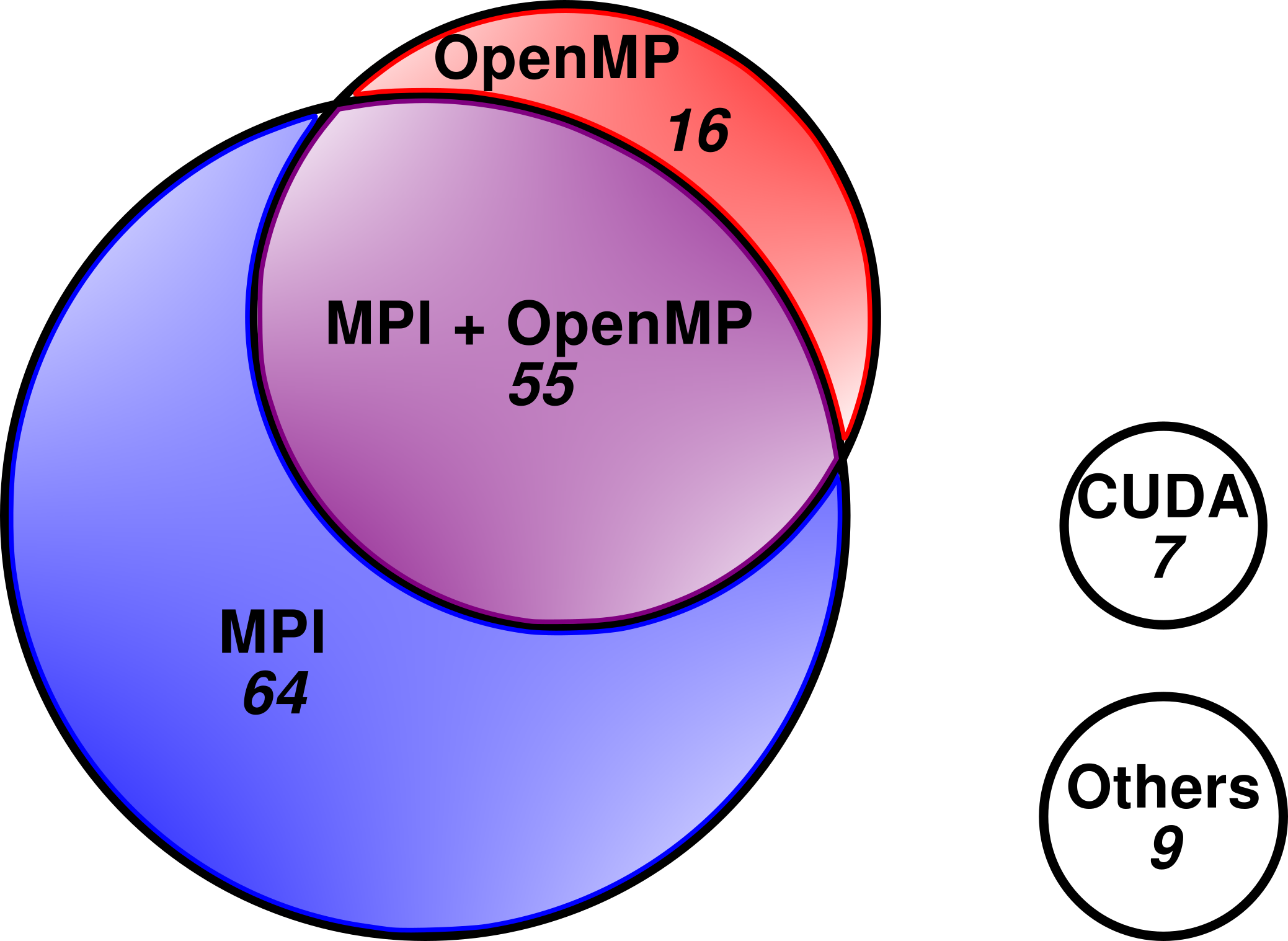
There is again an "Others" category, but unlike the corresponding category for the languages every member of this set is unique. Examples of the other types of parallelism we have seen include Intel Threading Building Blocks (TBB) and Coarray Fortran.
Causes of Low Efficiencies
The POP Efficiency Metrics provide a methodology for characterising the performance of parallel code and for providing insight into where the most pressing problems lie. Looking across all the POP studies we can use the metrics to discern whether there are any overarching performance trends.
We found that 66% of analysed codes had a Parallel Efficiency less than 80%, and so we felt they required improvement to run efficiently in parallel. Indeed, 22% of codes have Parallel Efficiency below 50%, which means that less than half of their runtime is dedicated to computation. Note that analysis generally omits initialisation and finalisation, so in practice their efficiency is even worse.
Looking at the actual numbers reported in the studies we find that Load Balance Efficiency is often either very good or very bad. This suggests that load balance is something you have to actively pay attention to getting right or else it can go very wrong.
We can also use the hierarchical nature of the metrics to look at the common underlying causes of low efficiencies. Low Communication Efficiency is mostly caused by data transfer (high volume of data or high number of communications) rather than serialisation of communication. Low Computation Efficiency is often caused by poor instructions scalability rather than reduced IPC values; when strong scaling, growth in the total number of instructions executed often corresponds to undesirable code replication.
We can look further at the sorts of problems to see if there's any link to be drawn between programming approach and the types of problems experienced. Although there was no obvious correlation between language and inefficiency (e.g. we couldn't conclude things like "C programmers were more likely to write badly load-balanced code"), there was an interesting distinction to be drawn based on the type of parallelism the code employed.
For each study we recorded the main cause of inefficiency that was identified (i.e. load balance, computation or communication) and looked at how this varied across the three main types of parallelism:

From the graph we can see that studies of hybrid codes were much more likely to report problems with load balance than studies of pure MPI or pure OpenMP codes. This is perhaps understandable: when writing hybrid code you need to take into account both how the work is divided across MPI ranks and also how it is split up between participating threads on a rank.
Summary
-
There is more to HPC than running on 10,000 cores of the largest supercomputers. 80% of POP studies were on codes that targeted between 10 and 1,000 cores.
-
Fortran and MPI are the most popular languages/paradigms, but a large number of others are in use too. Performance optimisation tools and methodologies must therefore accommodate them.
-
There was no obvious correlation between the number of cores used and the efficiencies achieved; efficiency is more a characteristic of the code, and particularly how the code is parallelised. Hybrid codes are more likely to suffer from load balance issues, while pure MPI/OpenMP codes typically have issues with computation or inter-process/thread communication.
-- Nick Dingle (NAG)