Attempting to optimise performance of a parallel code can be a daunting task, and often it is difficult to know where to start. For example, we might ask if the way computational work is divided is a problem? Or perhaps the chosen communication scheme is inefficient? Or does something else impact performance? To help address this issue, POP has defined a methodology for analysis of parallel codes to provide a quantitative way of measuring relative impact of the different factors inherent in parallelisation. This article introduces these metrics, explains their meaning, and provides insight into the thinking behind them.
A feature of the methodology is that it uses a hierarchy of metrics, each metric reflecting a common cause of inefficiency in parallel programs. These metrics then allow comparison of parallel performance (e.g. over a range of thread/process counts, across different machines, or at different stages of optimisation and tuning) to identify which characteristics of the code contribute to inefficiency.
The first step to calculating these metrics is to use a suitable tool (e.g. Extrae) to generate trace data whilst the code is executed. The traces contain information about the state of the code at a particular time (e.g. it is in a communication routine or doing useful computation) and also contains values from processor hardware counters (e.g. number of instructions executed, number of cycles).
The metrics are then calculated as efficiencies between 0 and 1, with higher numbers being better. In general, we regard efficiencies above 0.8 as acceptable, whereas lower values indicate performance issues that need to be explored in detail. The ultimate goal then for POP is rectifying these underlying issues, e.g. by the user, or as part of a POP Proof-of-Concept activity.
The approach outlined here is applicable to various parallelism paradigms, however for simplicity the POP metrics presented here are couched in terms of a distributed-memory message-passing environment (e.g. MPI). For this the following values are calculated for each process from the trace data: time doing useful computation, time in communication, number of instructions & cycles during useful computation. Useful computation excludes time within the overheads of parallelism.
At the top of the hierarchy is Global Efficiency (GE), which we use to judge overall quality of parallelisation. Typically, inefficiencies in parallel code have two main sources: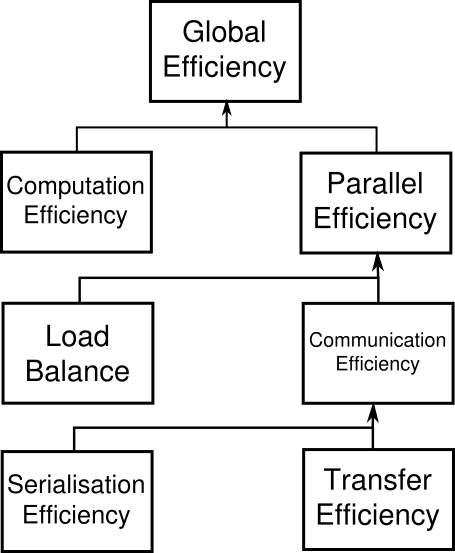
-
Overheads imposed by the parallel nature of a code
-
Poor scaling of computation with increasing numbers of processes
and to reflect this we define two sub-metrics to measure these two inefficiencies. These are Parallel Efficiency and Computation Efficiency, and our top-level GE metric is the product of these two sub-metrics:
GE = Parallel Efficiency * Computation Efficiency
Parallel Efficiency (PE) reveals the inefficiency in splitting computation over processes and then communicating data between processes. As with GE, PE is a compound metric whose components reflects two important factors in achieving good parallel performance in code:
-
Ensuring even distribution of computational work across processes
-
Minimising time communicating data between processes
These are measured with Load Balance Efficiency and Communication Efficiency, and PE is defined as the product of these two sub-metrics:
PE = Load Balance * Communication Efficiency
Load Balance (LB) is computed as the ratio between average useful computation time (across all processes) and maximum useful computation time (also across all processes):
LB = average computation time / maximum computation time
Communication Efficiency (CommE) is the maximum across all processes of the ratio between useful computation time and total runtime:
CommE = maximum computation time / total runtime
CommE identifies when code is inefficient because it spends a large amount of time communicating rather than performing useful computations. CommE is composed of two additional metrics that reflect two causes of excessive time within communication:
-
Processes waiting at communication points for other processes to arrive (i.e. serialisation)
-
Processes transferring large amounts of data relative to the network capacity
These are measured using Serialisation Efficiency and Transfer Efficiency. In obtaining these two sub-metrics we first calculate (using the Dimemas simulator) how the code would behave if run on an idealised network where transmission of data takes zero time.
Serialisation Efficiency (SerE) describes any loss of efficiency due to dependencies between processes causing alternating processes to wait:
SerE = maximum computation time on ideal network / total runtime on ideal network
Transfer Efficiency (TE) measures inefficiencies due to time in data transfer:
TE = total runtime on ideal network / total runtime on real network
These two sub-metrics combine to give Communication Efficiency:
CommE = Serialisation Efficiency * Transfer Efficiency
The final metric in the hierarchy is Computation Efficiency (CompE), which are ratios of total time in useful computation summed over all processes. For strong scaling (i.e. problem size is constant) it is the ratio of total time in useful computation for a reference case (e.g. on 1 process or 1 compute node) to the total time as the number of processes (or nodes) is increased. For CompE to have a value of 1 this time must remain constant regardless of the number of processes.
Insight into possible causes of poor computation scaling can be investigated using metrics devised from processor hardware counter data. Two causes of poor computational scaling are:
-
Dividing work over additional processes increases the total computation required
-
Using additional processes leads to contention for shared resources
and we investigate these using Instruction Scaling and Instructions Per Cycle (IPC) Scaling.
Instruction Scaling is the ratio of total number of useful instructions for a reference case (e.g. 1 processor) compared to values when increasing the numbers of processes. A decrease in Instruction Efficiency corresponds to an increase in the total number of instructions required to solve a computational problem.
IPC Scaling compares IPC to the reference, where lower values indicate that rate of computation has slowed. Typical causes for this include decreasing cache hit rate and exhaustion of memory bandwidth, these can leave processes stalled and waiting for data.
We sincerely hope this methodology will be adopted by our users and others and will form part of the project's legacy. If you would like to know more about the POP metrics and the tools used to generate them please check out the rest of the Learning Material on our website, especially the document on POP Metrics.