Vampire is a general purpose software package for simulating magnetic materials with atomic resolution. It is designed to cope with a wide range of magnetic phenomena, including ferro, ferri and antiferromagnets, and it can simulate a variety of structural media, including bulk systems, thin films and nanoparticles. It is written in C++ and parallelised using MPI.
POP conducted a Performance Audit to identify potential areas for improvement. This identified that the code could benefit from increased vectorisation. This was investigated further in a Proof of Concept report:
- The original scalar random number generator was replaced with calls to the Intel MKL Vector Statistics Library, which contains vectorised random number generators.
- Intel's Vector Advisor tool was used to analyse for-loops in the code. It was found that the compilers were failing to vectorise a number of loops due to assumed data dependencies. Further investigation revealed that there were, in fact, no such dependencies, so that the loops could be vectorised using the
#pragma omp simddirective. - Array refactoring and data alignment were also investigated, to improve the efficiency of cache-use in the code.
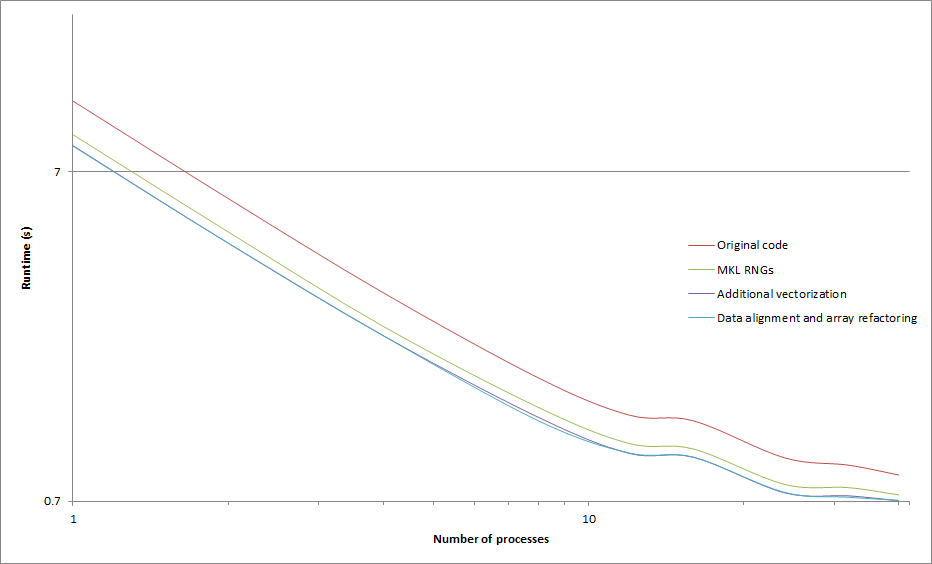
Figure 1. Runtimes for the region of interest for the original Vampire code, together with various modifications.
The code changes were tested on an Intel Xeon 6148 processor containing 20 cores and providing up to 40 hardware threads. Results for one test case are shown in the figure above. Depending on the number of processes, switching to vectorised random number generators resulted in up to a 27% performance improvement. When the #pragma omp simd directive was used to enforce loop vectorisation up to an additional 15% improvement was obtained. Data alignment and array refactoring resulted in minimal improvements to the runtime. Overall, up to a 46% performance improvement in runtime was achieved over the original code. The drop off in scaling performance on higher core counts was found to be caused by memory bandwidth contention.