Introduction
![]() TALP [1] (Tracking Application Live Performance), is a lightweight profiling tool specifically developed to deliver parallel efficiency metrics during production-scale HPC runs within the DLB library.
TALP [1] (Tracking Application Live Performance), is a lightweight profiling tool specifically developed to deliver parallel efficiency metrics during production-scale HPC runs within the DLB library.
TALP is the lightweight profiling module of the DLB library, designed to monitor application performance in real time with minimal overhead. Its goal is to provide actionable efficiency metrics that help users and tools identify bottlenecks, guide optimization efforts, and support adaptive runtime decisions. The module is non-intrusive, portable, and designed to complement traditional performance analysis approaches, ensuring seamless integration into diverse HPC environments.
Built with scalability and extensibility in mind, TALP supports both online and post-mortem performance analysis. It gathers parallel efficiency metrics derived from the well-established POP methodology, enriched with hardware counter information and raw measurements that allow users to define custom indicators. Relying on standard interfaces such as PMPI and OMPT, it operates transparently without requiring code modifications. For advanced use cases, a user-level API enables developers to annotate specific code regions and obtain detailed metrics tailored to their analysis needs.
Release 3.6.0 of DLB library comes with relevant new features in the TALP module, including now hybrid MPI+GPU efficiency metrics.
DLB 3.6.0 introducing MPI+GPU efficiency metrics
The well-known POP metrics for MPI applications have long been used in profiling and tracing tools such as Scalasca, Cube, and Paraver to identify performance bottlenecks in parallel CPU executions. However, as GPU-accelerated systems become common in HPC, these CPU-centric metrics alone are no longer sufficient. The new GPU extension to the TALP efficiencies introduces a set of metrics that capture the complexity of parallel GPU executions.
On the host side, the key metric is Device Offload Efficiency, while on the device side, the new metrics include Device Load Balance, Communication Efficiency, and Orchestration Efficiency. Together, these metrics help pinpoint possible performance bottlenecks in an execution.
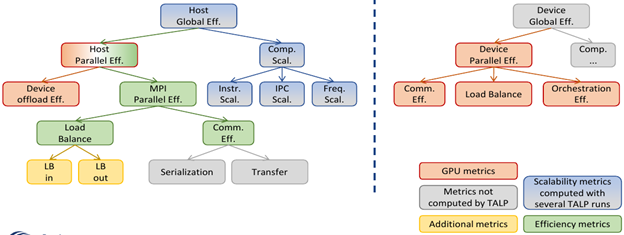
GPU Efficiency Metrics
-
Device Offload Efficiency (Host) quantifies the loss in efficiency when delegating work from CPU to GPU. Low values indicate that CPUs are mostly waiting on GPU-related calls such as data transfers, kernel launches, or synchronizations. The overall host-side Parallel Efficiency can be obtained by multiplying Device Offload Efficiency and MPI Parallel Efficiency.
-
Device Load Balance (Device) measures inefficiencies due to uneven kernel execution times across GPUs.
-
Communication Efficiency (Device) reflects the cost of data transfers, whether between GPUs (GPU–GPU) or between CPU and GPU.
-
Orchestration Efficiency (Device) represents idle periods when no useful GPU work is scheduled, indicating underutilization.
By multiplying original MPI POP metrics and Device offload efficiency, you can have the value for Parallel Efficiency. Multiplying the device-side metrics gives the global Device Parallel Efficiency. Metrics and Parallel Efficiencies on host and device are completely independent from one and other. By combining both host and device efficiencies, users can gain a comprehensive view of performance across CPU–GPU workflows.
Using TALP on HPC Clusters
TALP is part of the DLB (Dynamic Load Balancing) library and now includes support for NVIDIA and AMD GPU metrics. To use TALP on HPC clusters, users can use pre-installed modules, or check the installation guide.
Once installed, enable GPU profiling by selecting the CUPTI plugin, loading the appropriate dlb_mpi library, and preloading it before launching your application:
module load nvidia-hpc-sdk # ensure compatible version module load dlb export DLB_ARGS="--talp --plugin=cupti" preload="$DLB_HOME/lib/libdlb_mpi.so" srun ... env LD_PRELOAD="$preload" ./app
A hybrid MPI+GPU execution will result in an output similar to this:
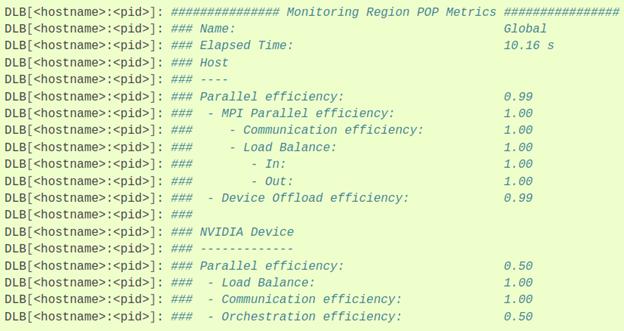
Summary
By integrating GPU-aware POP metrics, TALP-GPU bridges the gap between CPU and GPU performance analysis. Its host-device efficiency models provide actionable insights into hybrid application bottlenecks, making it a valuable tool for optimizing performance on modern heterogeneous HPC systems.
More Information
[1] Victor Lopez, Guillem Ramirez Miranda, and Marta Garcia-Gasulla. 2021. TALP: A Lightweight Tool to Unveil Parallel Efficiency of Large-scale Executions. In Proceedings of the 2021 on Performance EngineeRing, Modelling, Analysis, and VisualizatiOn STrategy (PERMAVOST '21). DOI:10.1145/3452412.3462753
[2] Rahimi, Ghazal, Victor Lopez, Marc Clascà, Joan Vinyals Ylla Català, Jesus Labarta, and Marta Garcia-Gasulla. Hardware-Agnostic and Insightful Efficiency Metrics for Accelerated Systems: Definition and Implementation within TALP. Preprint
Download: https://pm.bsc.es/dlb-downloads
User guide: https://dlb-docs.readthedocs.io/en/stable/how_to_run_talp.html