Polar Scat is an atmospheric physics code that computes scattering cross sections for particles in the atmosphere. It is written in Fortran and parallelized with OpenMP. A POP performance assessment was performed, showing that the parallel performance of the code was excellent, with a global efficiency of over 80% on 48 cores. However, vectorization was poor, with only 29% of vector capacity usage on 48 threads.
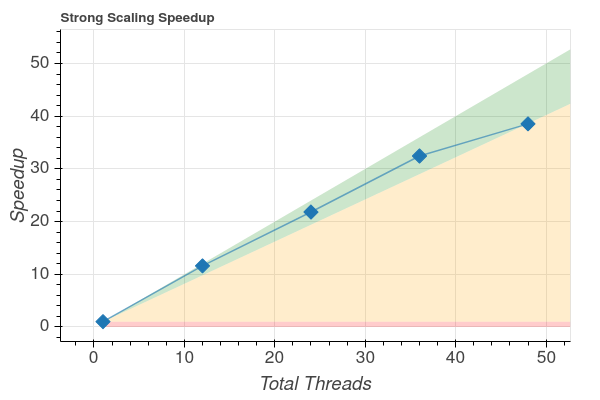
Fig 1: Strong scaling speedup for the original code.
The cause of this poor vectorization was traced to a single nested loop (the outer loop of which was parallelized) involving multiple operations on arrays of size 3. The hope was that if the innermost loop could be refactored, then vectorization might be improved, yielding performance improvements on all core counts. In the POP assessment, two approaches were suggested.
- Approach 1 was to explicitly unroll the array operations and refactor the loop to allow the compiler to vectorize it.
- Approach 2 was to remove the loop altogether, replacing it with matrix operations using matrices formed by concatenating the small arrays.
The goal of the proof-of-concept was to implement these two approaches and investigate their effect on the performance of the code.
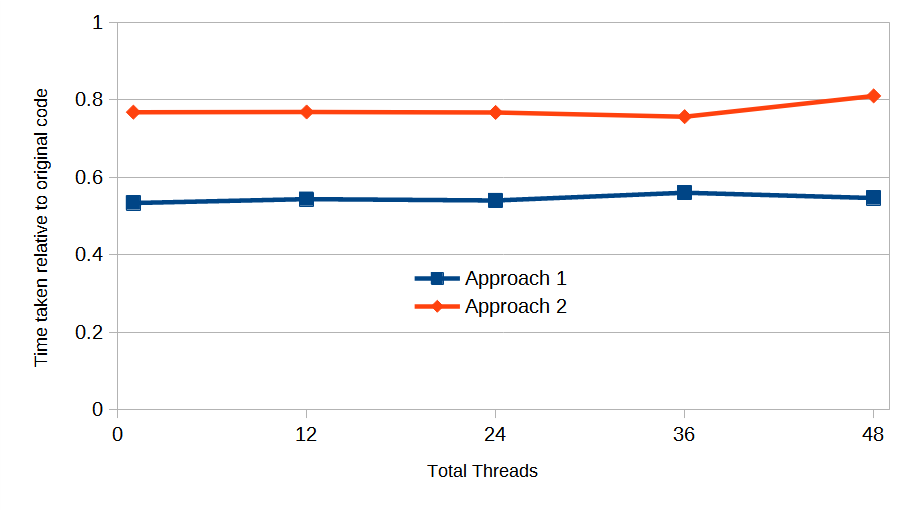
Fig 2: Performance of amended codes relative to original code.
As shown in Figure 2, Approach 1 was almost twice as fast as the original code whereas Approach 2 gave an approximately 1.3x speedup. Vector capacity usage for both approaches was over 99%. However, in order to get Approach 1 to work, the compiler directive !$OMP SIMD REDUCTION had to be used with the reduction on an array. This is a fairly recent addition to the OpenMP standard so makes the code less portable. Approach 2 only requires access to a good BLAS implementation for DGEMM and ZGEMM calls.
-- Edvin Hopkins (NAG)