Modelling large and complex data sets is a major problem today. Examples here are the modelling of movie ratings using the Netflix dataset with more than 100 Million entries or the prediction of compound-on-target-activity in chemogenomics from the ChEMBL data set with more than 2 Million compound records. The compound-on-target-activity study at large scale is an extremely important question in the process of discovering new drugs, which is currently addressed in the ExCAPE project. The Bayesian Probabilisitc Matrix Factorization (BPMF) is an efficient method to solve these kind of complex modelling problems.
The public available BPMF code was analysed in a POP Audit and Performance Plan service activity. While the BPMF code that showed already good scalability over several 100 nodes and also good efficiency on the node level, POP experts could still identify points for improvement.
So a follow up Proof of Concept study was performed together with the customer. During the study several points were addressed:
- Further optimization of the linear algebra computations
- Improvement of the selection of the optimized algorithms inside BPMF
- Solving load balance issues in the OpenMP parallelization
The linear algebra operations inside BPMF make use of the very efficient and well vectorizing Eigen Library. But the POP experts were able to identify some improvements due to mathematical properties of the matrices saving a good margin of CPU operations in some parts of the code.
BPMF comes already with different flavours of algorithms that are optimized for data element sizes. A crucial point now is the selection process when to use which algorithm. A closer look at the switching points lead here to another improvement.
The last and most challenging issues nevertheless was load balance. Due to the nature of the problems solved with BPMF, the datasets include very inhomogeneous data, which result in load balance problems in the parallelization. BPMF therefore comes with a hybrid MPI+OpenMP parallelization. The still existing load balance problem found was at the lower OpenMP level. Here a single level OpenMP parallelization was used on the node level.
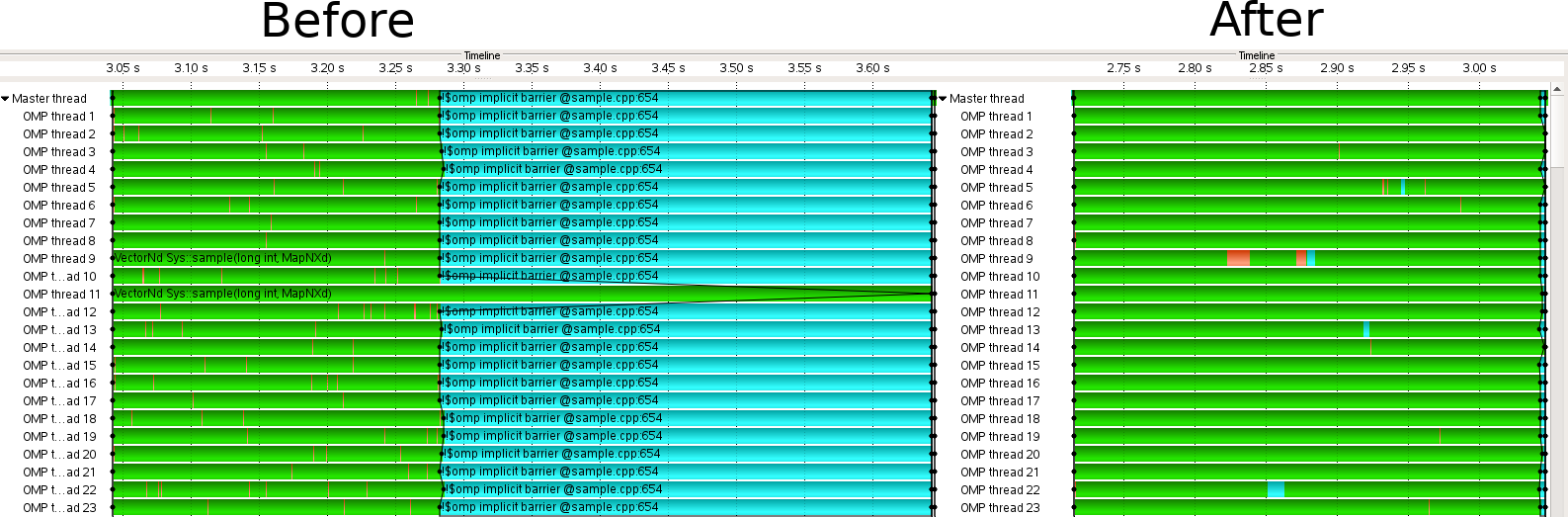
The POP experts now implemented a second nesting level and made also use of OpenMP tasks, which solved the load balance problem: Originally the load balance of the problematic code part was 42.5% – after the modifications 98,9%.
Finally, the improvements made in this POP Proof of Concept were evaluated with three different datasets achieving speedups between 1.6 and 1.8 that correspond to runtime reductions between 38 and 44%.