ParMmg is an open-source software developed at INRIA for parallel mesh adaptation of 3D volume meshes. The parallel mesh adaptation algorithm is based on iterative remeshing and repartitioning of the distributed mesh. It uses the Mmg software to perform the sequential remeshing steps. The application is written in C and C++ and parallelized with MPI. We used a weak scale input from 2 to 256 MPI ranks for the analysis.
During the initial analysis of the application, we applied the POP methodology and detected two significant inefficiency sources: load balance and instruction scalability. The load imbalance was caused due to an uneven distribution of computation between MPI processes. Regarding the instruction scalability, the problem was localized in the communication phase of the iterations, which had a loop that escalated quadratically with the number of MPI ranks.
Our suggestions to address these issues are, on the one hand, to implement the communication phase avoiding a quadratic number of iterations. On the other hand, we propose a proof-of-concept to address the load imbalance problem by using the DLB library.
With the suggestions of the first analysis, the developers were able to change the MPI communication pattern to a more efficient one. Figure 1 shows the performance improvement of these changes compared to the initial version of the code. We can see how the new code is slightly worse when using a low number of MPI ranks, but it achieves a 1.76x speedup with 256 MPI ranks.
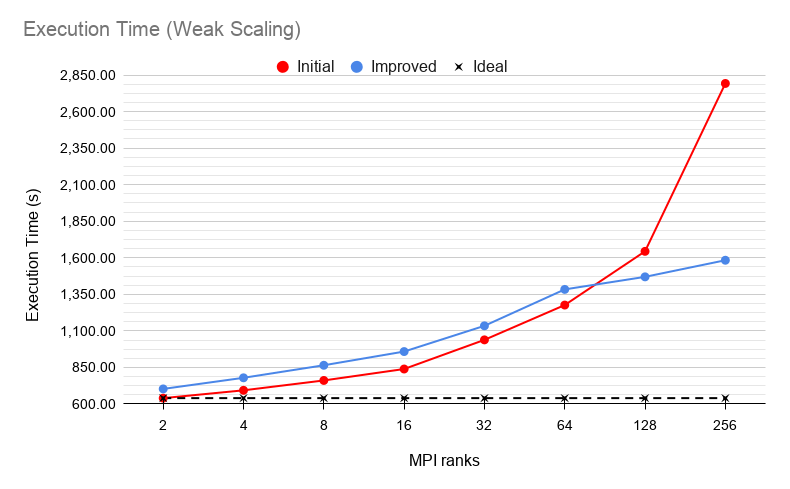
Fig. 1. ParMng scaling of Initial (red) and Improved (blue) version.
Starting from that improved version, we addressed the load balance problem in a Proof of Concept (PoC) using the Dynamic Load Balance (DLB) library. For that purpose, we had to implement a shared memory parallelization of the imbalanced region since it’s a requirement for DLB. As the program wasn’t parallelized at that level yet, we decided to do it with the OmpSs programming model since it is the more stable and efficient model to work with DLB in the current version.
First, we did some code refactoring to make all the iterations independent and make the code compliant to the OmpSs model since it doesn’t allow certain statements inside a task (e.g., break and return). After that, we parallelized the loop using a task construct with the appropriate data sharing and defining a priority to execute bigger tasks as soon as possible. Finally, as DLB was intercepting all the MPI calls, but we just needed it to act at one point, we used a routine from the API called DLB_Barrier to use DLB only there and avoid further overhead. Figure 2 shows all the relevant changes introduced to the code.

Fig. 2. OmpSs taskification.
The final performance results are displayed in Figure 3. Compared to the initial version, the final version achieves a speedup of 2.02x with 256 MPI ranks and 1.15x compared to the Improved version.
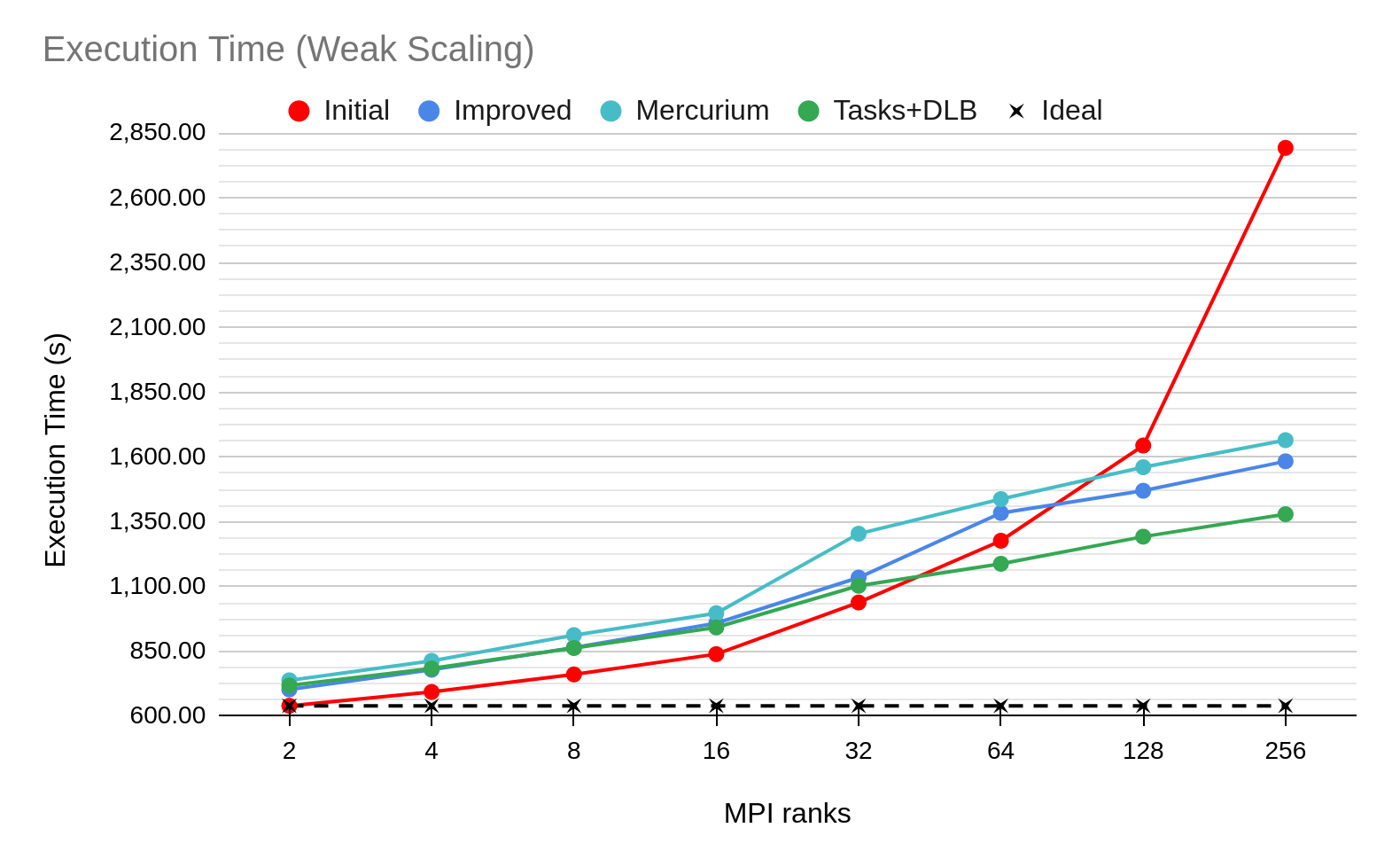
Fig. 3. ParMng scaling of Initial (red), Improved (blue) and final OmpSs tasks+DLB (green) version.
This work, including three kinds of POP services (Performance Assessment, Follow up, and Proof-of-concept), shows how we improved the performance of a production HPC application addressing its load imbalance and instruction scalability and allowing it to run 2x faster.
-- Joel Criado (BSC)