Project Background
immerFLOW is OPTIMAD proprietary finite volume Computational Fluid Dynamics (CFD) solver based on the Immersed Boundary (IB) method and on octree-based Adaptive Mesh Refinement (AMR) technology.
It is written in Modern C++ (C++11 standard), and it can use both MPI-only and hybrid MPI+OpenMP parallelism paradigms.
immerFLOW is based on bitpit, an open-source library for scientific computing, developed by us, OPTIMAD team. And, for now, it can solve for compressible and incompressible flow regimes.
Objective
Thanks to NAG we have got the opportunity to improve parallel HPC applications performance in the framework of an EU funded project, the POP project. This service was available for proprietary application too and it could provide both a Performance Assessment (PA) and recommendations on how to improve performance (Proof-of-Concept, PoC).
Before the experience with POP, immerFLOW had never been tested for scalability to a high number of processes and threads. We did limited tests to just one node with 20 cores, noting a weird behaviour of the hybrid OpenMP+MPI implementation: the more threads per rank we used, the worse the performance and the scaling were. Furthermore, we were interested in testing the pure MPI parallel code scalability to a much higher number of processes.
The Challenge
Senior software developers started working with NAG on both versions of the code: compressible and incompressible. NAG carried out performance and strong scalability analysis using Scalasca/ScoreP and Extrae software.
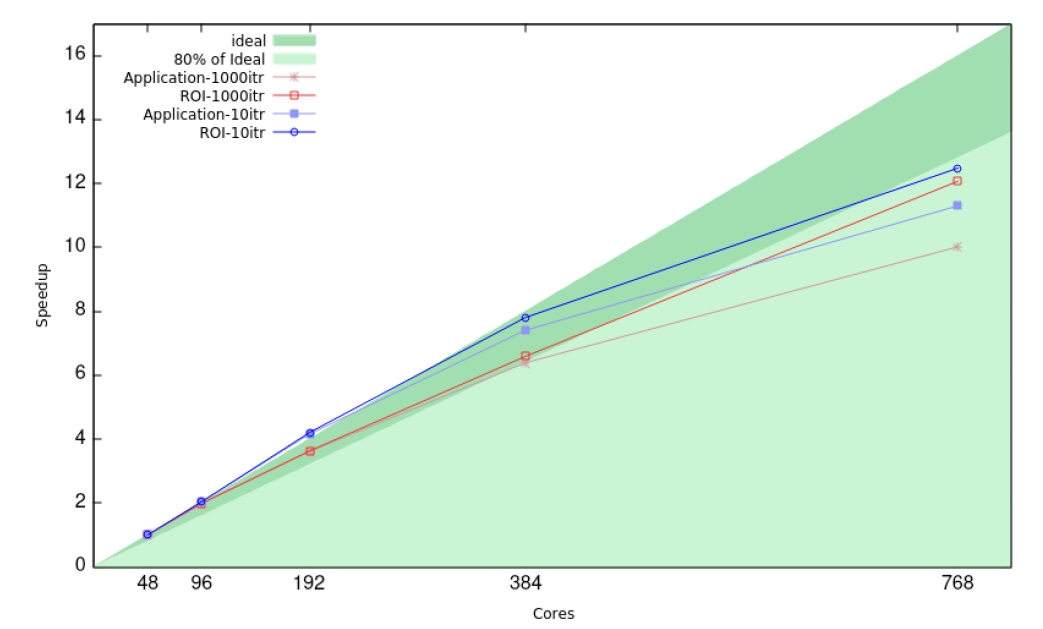
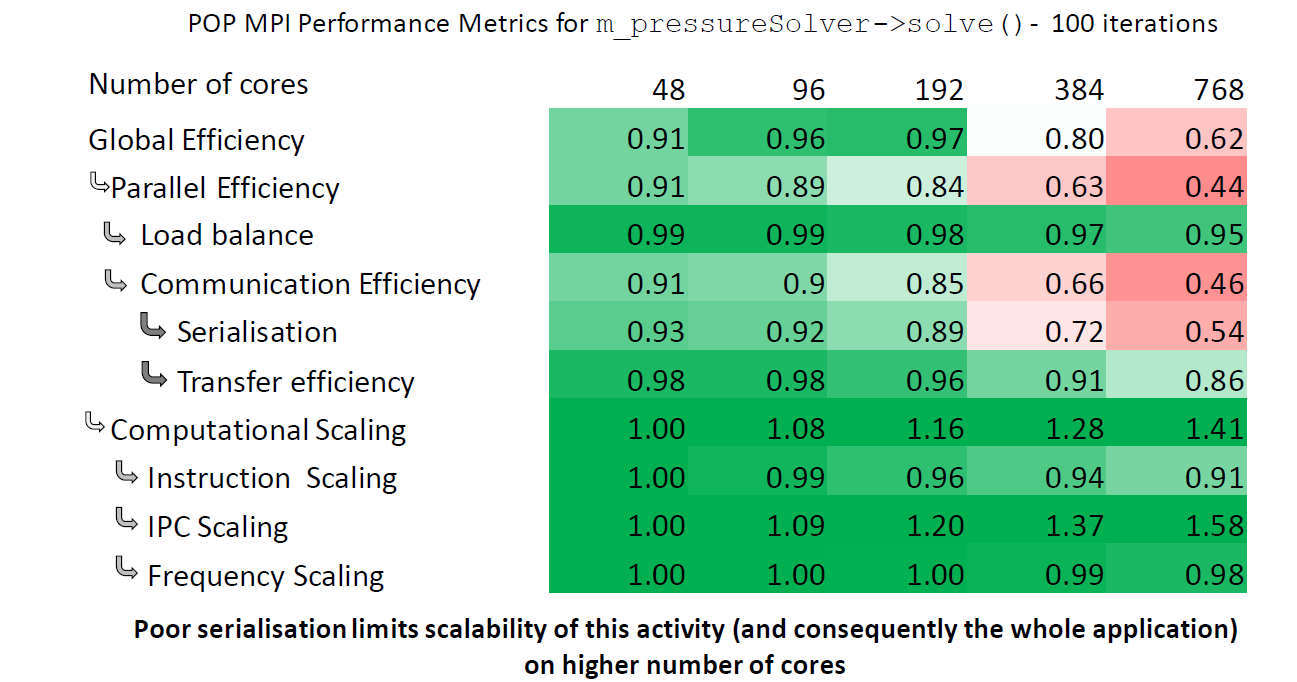
Performance Metrics and Overall Strong Scaling Behaviour Plots, focused on Regions of Interests (ROIs), were reported to us with an important insight on the most critical routines of the code (see figures).
 |
 |
| Fig. 1: Incompressible solver Performance Assessment (MPI-only) | |
 |
|
 |
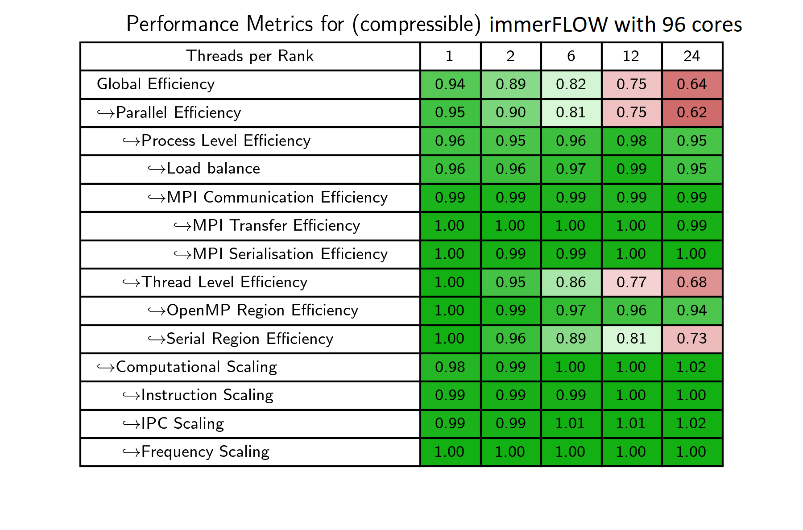 |
| Fig. 2: Compressible solver Performance Assessment (MPI_only and OpenMP+MPI) | |
The results of the PA confirmed our experience about the hybrid version of the (compressible) code and at the same time gave us a better understand of pure MPI strong scalability for both versions.
Compressible and incompressible solvers share the way they compute finite volume fluxes but, because of its integration method, the second makes a large use of the sparse linear system solvers library PETSc. And since this library is not able to exploit threads, neither is the parallel hybrid implementation of the incompressible solver. It does not exploit the threads efficiently along with all the time step integration algorithm. For this reason, the incompressible solver was analysed considering the pure MPI paradigm only.
Our results with POP
Incompressible solver
The Performance Assessment (see Fig 1) stated that the MPI Serialization is the main factor that limits scalability. And a further NAG’s investigation on serialisation sources indicated that the MPI collective and the imbalanced computation regions within the PETSc solver are the main causes of the serialisation on 768 cores run. Senior software developers did not proceed with the PoC for the incompressible version of the code, because the nature of the limiting factor was external to our solver. Despite that, NAG suggested us to pay attention to the choice of linear solver and the associated preconditioner, trying to find the best combination and the best values of the parameters defining the behaviour of these two components.
Compressible solver
Compressible Solver was more complex because no external libraries are involved, the flux computation algorithm structure is shared with the incompressible one and the parallel hybrid OpenMP+MPI paradigm is fully expressed.
NAG observed:
- MPI-only scaling is excellent up to 768 cores, but
- some sources of MPI serialization are visible moving to 1534 cores
- MPI Transfer Efficiency can be improved
- When MPI scaling is good OpenMP slows things down a little
- OpenMP may become helpful when MPI scaling starts to break down
NAG defined a PoC plan identifying a strategy, implementing OpenMP Tasks, and three related major modifications to improve the overall performance of the code:
- Improve hybrid performance by overlapping communication and computation
- Understand how to structure the code for kernel-based paradigms (e.g. CUDA)
- Improve data buffering efficiency in bitpit
With these indications, OPTIMAD modified Immerflow (V0 (original code) -> V2 (“taskified” version)) by introducing:
- OpenMP V4.5 for task-loop construct
- Identification of calculations that can be overlapped
- Task dependencies to overlap MPI communication
- Temporary data copies removal for efficiency
- Data sub-blocking removal when processing
- An attempt to remove atomics with no success because of slower alternatives
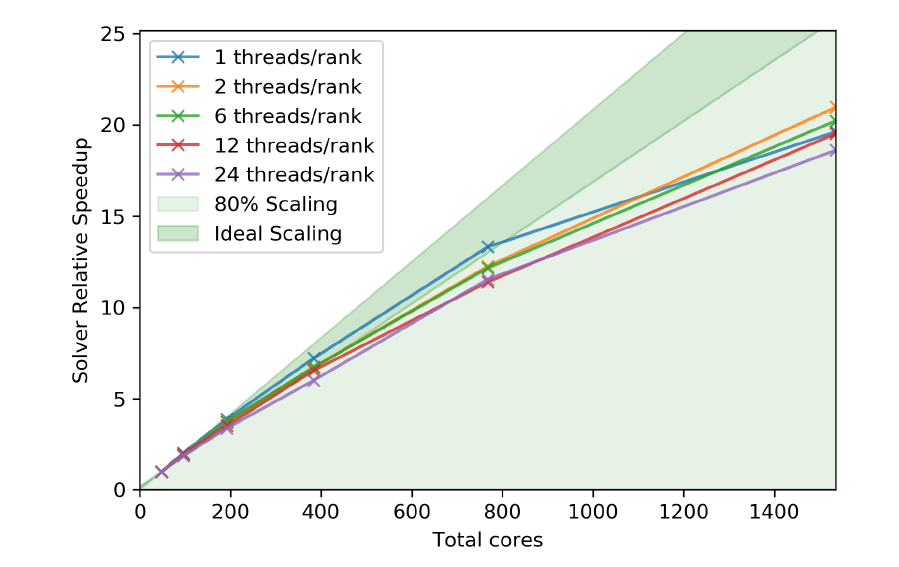
Using the new version of immerFLOW (V2) NAG re-analyse the code performance observing (Fig 3):
- An overall efficiency improvement in all the cases with respect to V0
- MPI-only remains the most efficient paradigm
- Largest gains in hybrid version at high thread counts
- ~10% MPI-only performance gain due to removal of temporary copies
- Small improvements in scaling
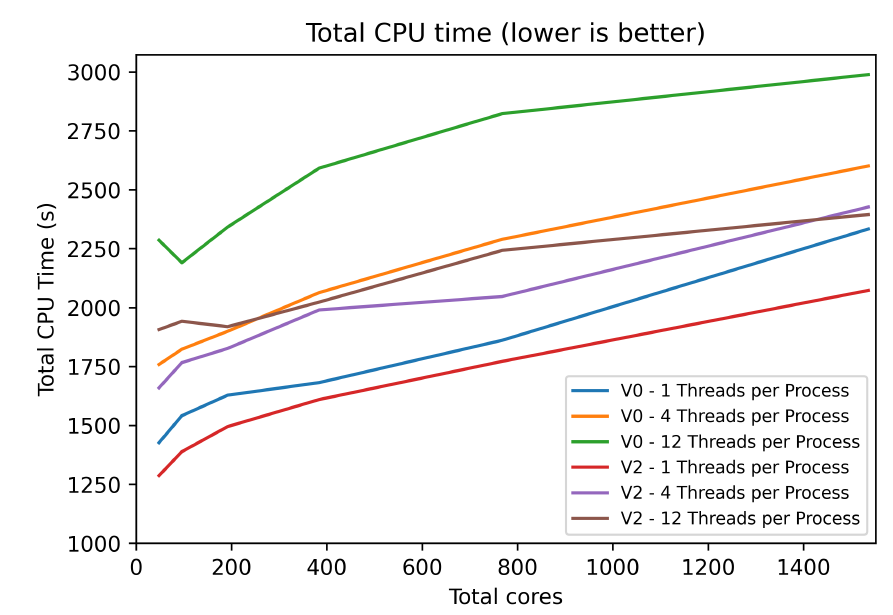 |
 |
| Fig. 3: Compressible solver scaling PoC results (OpenMP+MPI) | |
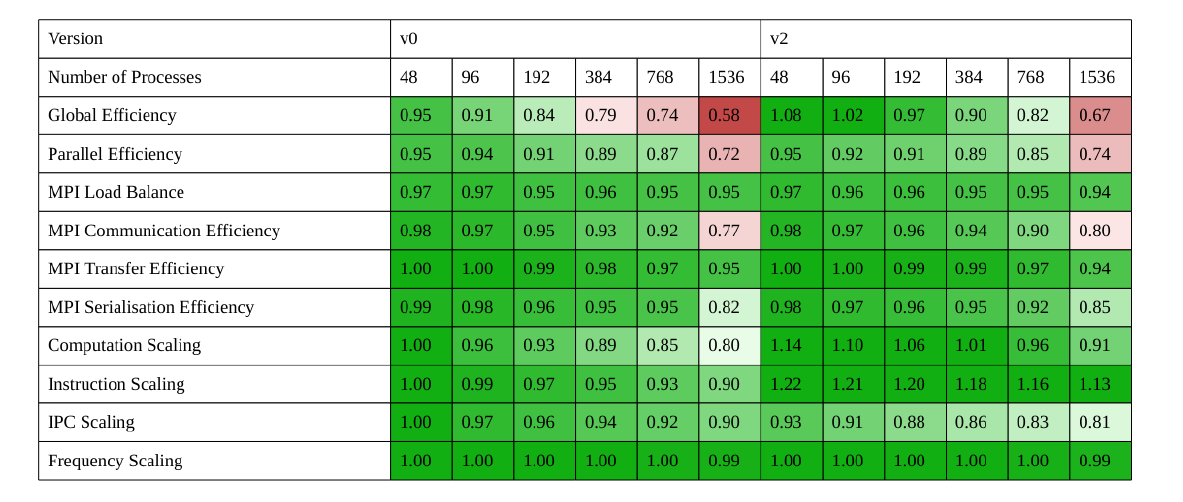
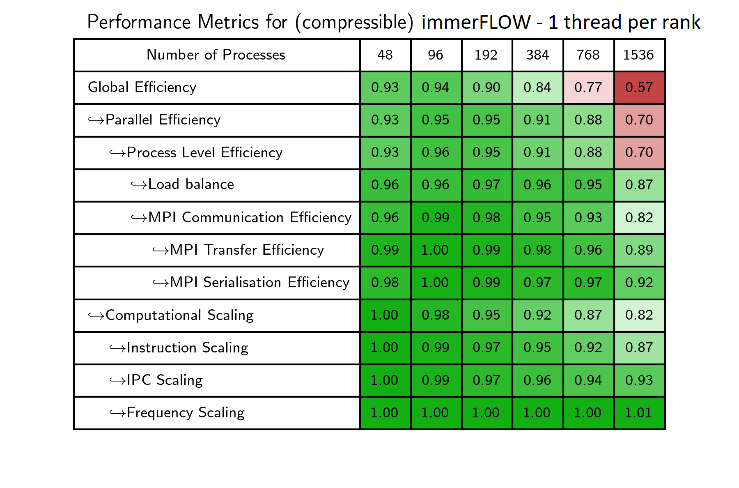
Fig. 4: Compressible solver metrics matrix comparison (MPI-only)
Using VTune, NAG was able to identify V2 code hotspots, observing how atomic lock contention is the primary issue for OpenMP performance. And our software developers tried to remove atomics but the found solution suffers of important data lookup overheads due to a large cache missing. These lookup overheads are widespread into the code and limit the overall performance suggesting a not easy re-thinking of the underlying data structure.
Finally, under the guidance of NAG we of OPTIMAD improved the use of memory pools, moving towards a simple static version using OpenMP “threadprivate”, resulting in a more efficient use of pools.
Conclusions
The work done in collaboration with NAG has been very important for our understanding of immerFLOW deep behaviour. Our software developers learnt many useful details thanks to the insight given by the Performance Metrics, discovering the primary issues limiting the performance. We can now re-design the solver using OpenMP tasks enabling slightly improved performance and scaling, and we can introduce the kernel-based paradigms that can be largely exploited in GPU programming.
Looking at Fig. 4, some open questions are still there but IPC hotspots have been identified and the suggestions from NAG can be considered for future improvements.
About OPTIMAD Srl
![]() OPTIMAD is an engineering consultancy and software-house, spin-off of the PoliTo (Politecnico of Turin), highly specialized in the solution of engineering problems. OPTIMAD builds and cultivates skills to develop three stand-alone and integrated tools that improve business workflows and reduce resources for his customers-partners. Through his state-of-the-art technologies OPTIMAD goes the extra mile and builds innovation together with the customers.
OPTIMAD is an engineering consultancy and software-house, spin-off of the PoliTo (Politecnico of Turin), highly specialized in the solution of engineering problems. OPTIMAD builds and cultivates skills to develop three stand-alone and integrated tools that improve business workflows and reduce resources for his customers-partners. Through his state-of-the-art technologies OPTIMAD goes the extra mile and builds innovation together with the customers.

