OPM Flow is an open-source reservoir simulator for three-phase flow problems using a fully-implicit mathematical formulation, and employing automatic differentiation to have a flexible numerical core. It is suitable for industrial simulation problems as well as for research purposes. OPM Flow is applied industrially in simulating oil recovery in fields on the Norwegian Continental Shelf, and for research on CO2 applications, e.g., CO2-enhanced oil recovery and CO2 sequestration. For more information, see https://opm-project.org.
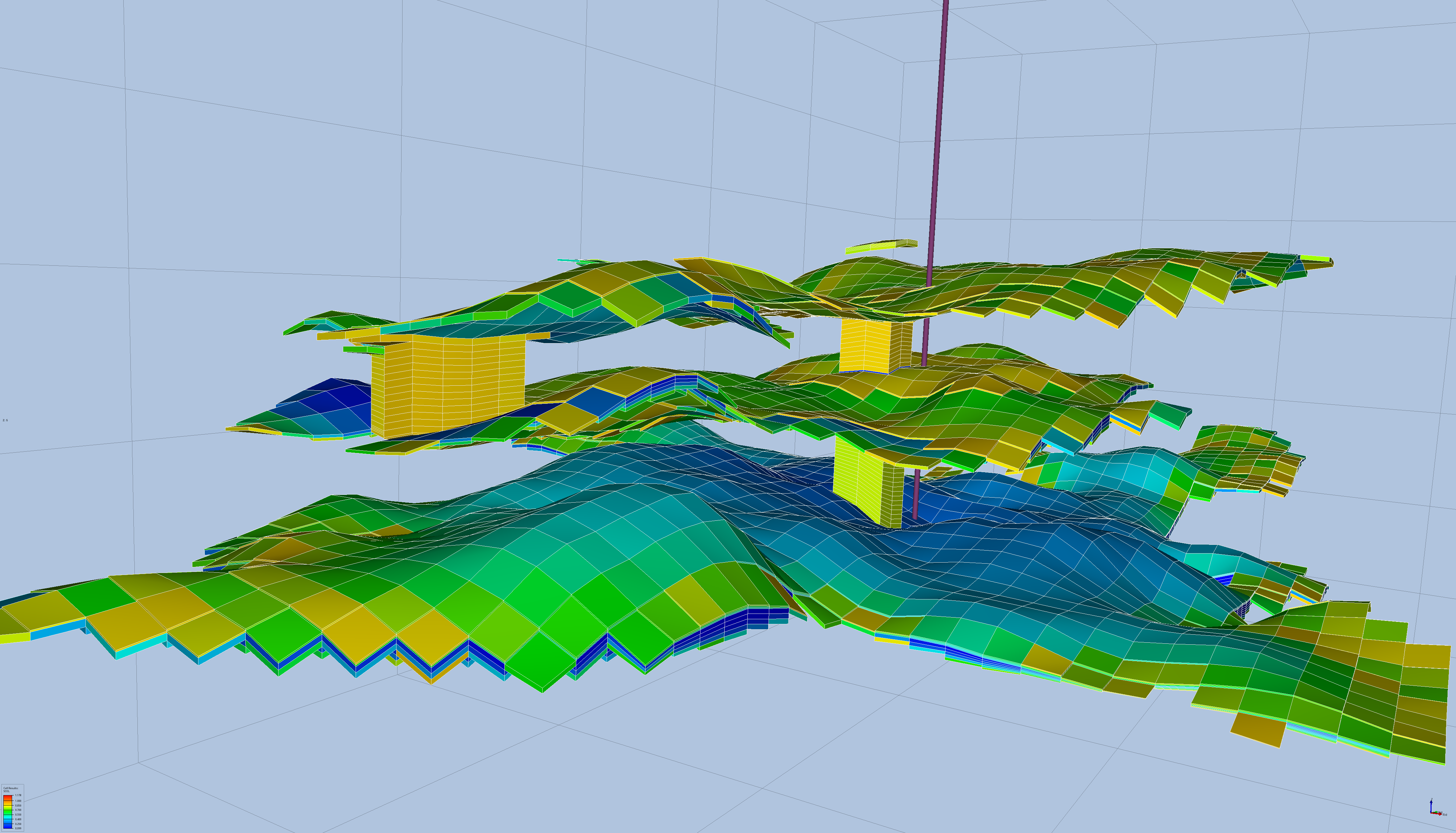
Fig 1.: Close view of CO2 plume of the Sleipner case, only showing cells with significant CO2 concentration. Figure made using the open source tool ResInsight.
OPM Flow uses a hybrid parallel programming model combining MPI and OpenMP. However, OpenMP is employed in specific code sections only. OPM Flow is developed by SINTEF, NORCE, Equinor and other partners. Currently, the performance of the simulator is tested and improved using supercomputers within the ACROSS project.
We inspected OPM Flow within a performance assessment with a request for finding potential bottlenecks and sources of performance limitations on which the developers should concentrate. We focused on the main iterative process which executes the runStep routine repeatedly. The measurements were performed on the Karolina supercomputer at IT4Innovations. We used 1 to 4 compute nodes, i.e., 128 to 512 CPU cores. The tested data set is called Sleipner which is interesting for studying long-term effects of storing CO2 underground. This is an open data set with an open license.
Our performance analysis reveals problems with load imbalance. This also affects serialization efficiency which reflects frequent waiting in blocking MPI calls (Allreduce and Waitany). We noticed very fine-grained computation that is alternated by communication (global and point-to-point) which negatively contributes to the imbalance and the decrease of serialization efficiency. We recommend reviewing the work distribution process implemented in OPM Flow. It is not optimal since the load between processes (and threads also) vary. Also, it would be beneficial to consider increasing the chunk size (to reduce frequent communication phases) or reducing the extensive usage of global communication. If there is a space for overlapping communication and computation it might be worth implementing this approach.
The partial usage of threads negatively affects the final score since the power of cores which were reserved for OpenMP is wasted during intervals where only processes are employed. However, it is a question whether it is possible to adjust the algorithms used in those code parts in order to introduce OpenMP there.
The largest run (4 compute nodes) struggles with noticeable instruction count increase. We checked that it is connected with an increase of solver iterations. We kept the default settings of the simulator for all the runs we executed which might not be optimal for the 4-node case. The iteration growth may negatively contribute to the previous load imbalance and the serialisation efficiency issues.
These are 3 main issues and challenges for the OPM Flow development team that we identified. We discussed them in detail during the final meeting with the representatives from SINTEF and their partners. The customers explained how some of the processes are implemented inside OPM Flow and started to think of possible solutions to the performance problems and their limitations.
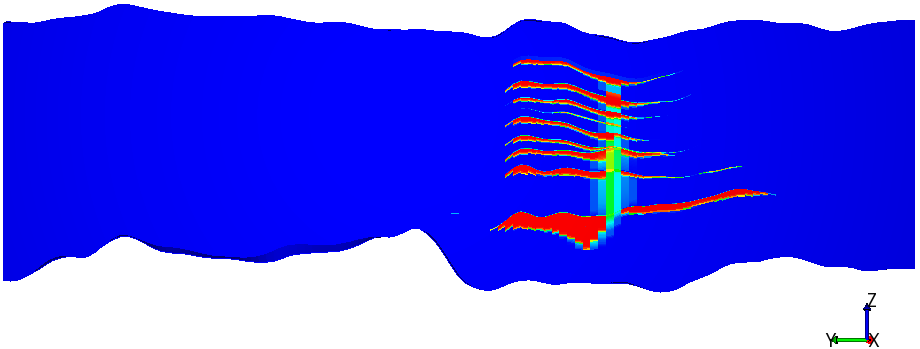
Fig 2.: Simulated CO2 concentration in the Sleipner benchmark case.
-- Tomáš Panoc (IT4I)