RoSSBi-3D (Rotating Systems Simulation for Bi-fluids) is the 3D version of a code specifically developed to study the evolution of protoplanetary disks. It is based on a previous 2D version which was revisited to build-up a new and high-performance 3D-code. It will be used to disentangle the observations of protoplanetary disks provided by the large ALMA array (see Figure 1). This project was developed at LAM (Laboratoire d’Astrophysique de Marseille, France.
This pure MPI Fortran code solves the fully compressible inviscid Euler’s equations for a perfect gas in non-homentropic conditions and for pressureless particles in a fluid approximation.
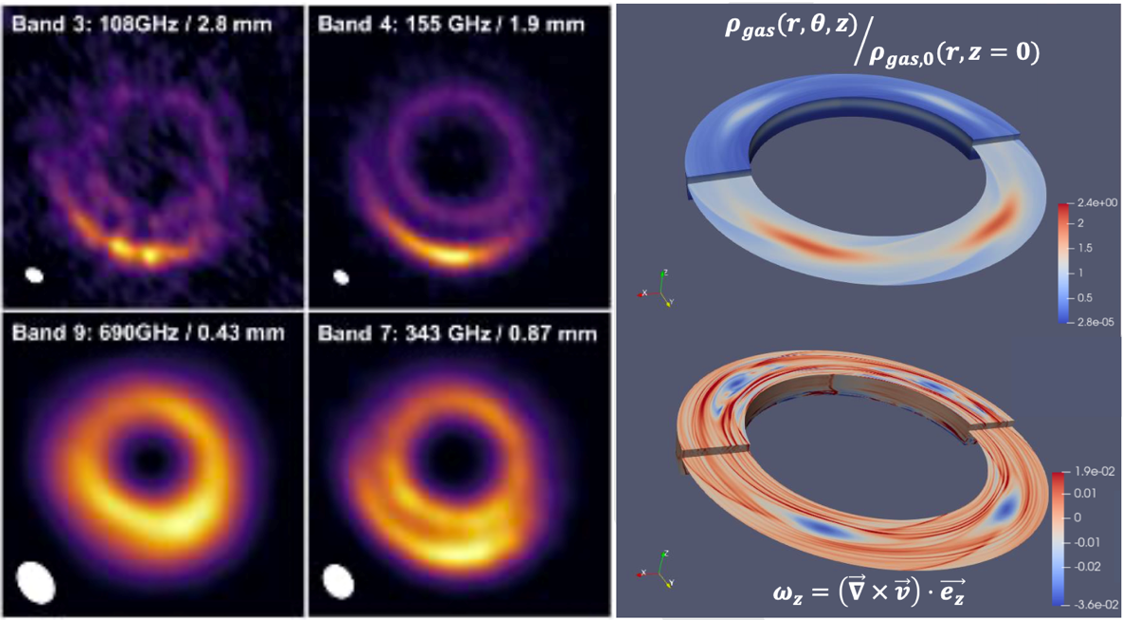
Fig. 1: ALMA observations and visualized simulations of possible vortices in protoplanetary discs.
The initial audit of the code was requested with the goal of identifying potential areas of improvement in large resolution simulations and reducing the runtime. It was also the first analysis of the code using any performance tools.
The code is intended to run very long simulations so, together with the large resolution of domains, the first challenge was to handle the enormous amount of data produced by the tracing tool. Using specific tracing techniques (e.g. burst mode tracing) we were able to determine the space-time behaviour of the application and effectively limit the representative portion of the runtime for the analysis.
During the standard POP analysis workflow, we identified several performance issues that limited the scalability and speed of computation. The POP metrics evaluation revealed significant drops in the Transfer efficiency and Instruction scaling that turned out to be related. The following analysis showed that the main limiting factor was an excessive number of MPI messages, transferring only small amounts of data with almost no computation between them. This issue was fixed by collapsing several thousand of the small messages into only a few tens of larger messages in each time step. This also reduced the loop overhead and improved the Instruction scaling. The second significant improvement to the Instruction scaling was brought by additional parallelization of a 3D domain in the remaining 2 directions. The insufficient parallelization in the initial version of the 3D code was indicated by metrics comparison with the 2D version.
| Version | initial | updated |
| Number of processes | 576 | 576 |
| Elapsed time (sec) | 7.59 | 1.56 |
| Efficiency | 0.18 | 0.95 |
| Speedup | 2.85 | 15.13 |
| Average IPC | 1.05 | 0.92 |
| Average frequency (GHz) | 2.52 | 3.25 |
Tab. 1: Metrics overview of the representative part of the initial and updated version of the code. The Efficiency and speedup are relative to the corresponding base runs (36 processes).
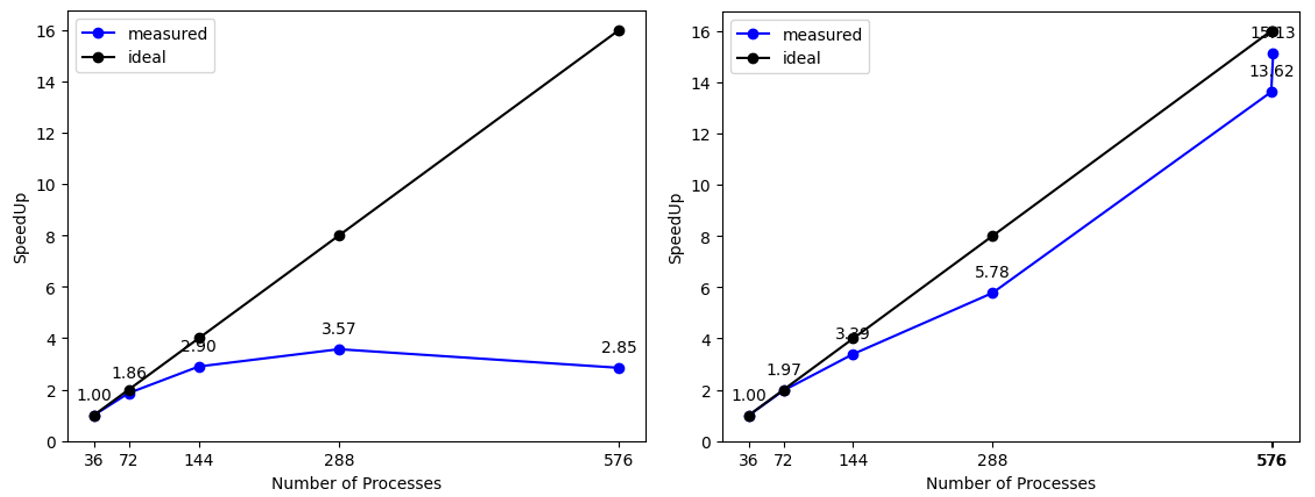
Fig. 2: Scalability of the original (left) and updated (right) version of the code.
After the code was updated, a follow-on audit was performed to verify the effect on performance of the implemented improvements and to reveal any newly produced bottlenecks. Table 1 and Figure 2 compare the key metrics and scalability of the initial and updated versions. The follow-on analysis found several additional areas for further improvement, including code vectorization and communication pattern tuning, and showed that the updated version of the code already reaches up to 4.9x speedup on 576 processes compared to the initial version.