The BDDCML library provides a scalable parallel solver of linear equations for systems originating from finite element computations. The implementation is based on the adaptive Multilevel Balancing Domain Decomposition by Constraints (BDDC) method, while reflecting some recent advancements in the field. Codes are written in Fortran 95 with MPI parallelization. The BDDCML library provides a simple interface callable from Fortran and C. For more information, follow the link: https://users.math.cas.cz/~sistek/software/bddcml.html.
The library was analyzed within a POP performance assessment and at the time of writing, a follow-on analysis is in process. This code is the first one analyzed for energy inefficiency in the POP2 project.
Energy efficiency measurement and tuning
The analysis was done using the open-source runtime system MERIC, developed at IT4Innovations. This tool supports a wide range of power monitoring systems, and various hardware parameters, that can be tuned during the application runtime. For each part of the application with a specific behavior, a configuration is identified in which the energy savings get close to the maximum, while the performance is almost unaffected. In this case, CPU core and uncore frequencies were tuned. The uncore refers to the on-chip subsystem of Intel processors, shared by multiple cores, such as the on-chip interconnect or last level cache. Intel Running Average Power Limit (RAPL) performance counters and the Atos|Bull High Definition Energy Efficiency Monitoring (HDEEM) on board integrated system were used for power monitoring and energy consumption measurements, both working at a 1 kHz sampling frequency.
MERIC not only identifies the optimal configuration for each of the instrumented regions, but also performs dynamic tuning during production runs of the application, with minimum overhead caused by the tool itself.
The results presented show the application behavior when executed on six dual socket nodes, consisting of Intel Xeon E5-2697v4 codename Broadwell (145W TDP, 18 cores) processors. They allows the tuning of the frequency of the cores in a range from 1.2 to 2.3 GHz nominal frequency, and 3.6 GHz turbo, as well as the uncore frequency of this chip, which starts at 1.2 GHz and goes up to 2.8 GHz.
The application profile
The MERIC workflow starts with application instrumentation, which can be done automatically. In this case thirteen regions were identified, for which various configurations of the tuned parameters were tested to identify the optimal configuration.
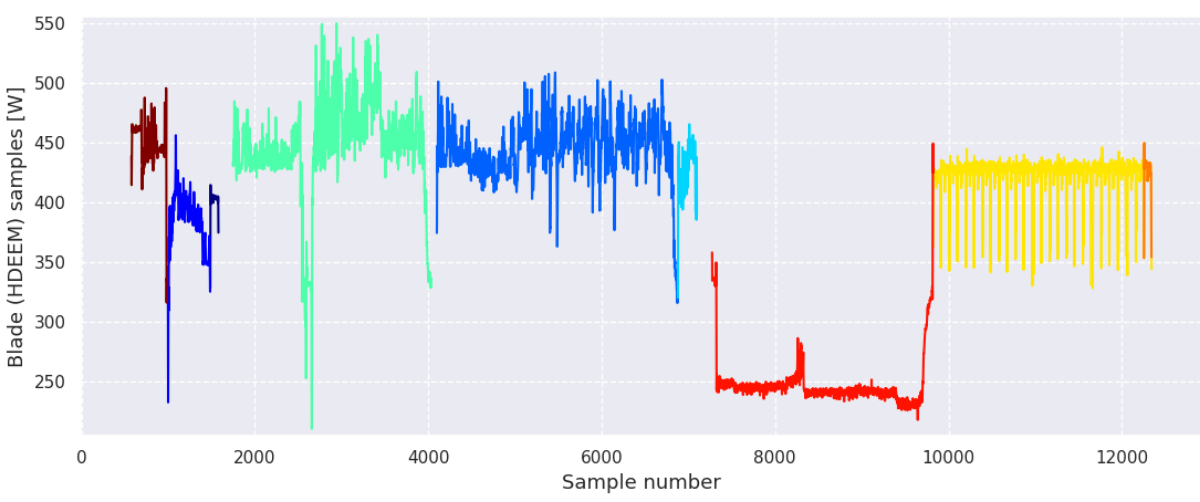
Fig. 1 Power consumption of a single blade. Each color represents one of the last-level instrumented regions.
The power consumption timeline of last-level regions shows not only the power consumption variability of over 300W during the application run, but also the dynamicity of the main loop (yellow part of the graph), or major runtime coverage, too. The power consumption timeline of the blade components reveals other details, especially memory loads, which is the information that may help us identify the optimal configuration of the frequencies. Another interesting piece of information is that the CPUs very occasionally attacked the TDP under this workload, so no radical power capping could be performed without performance loss.
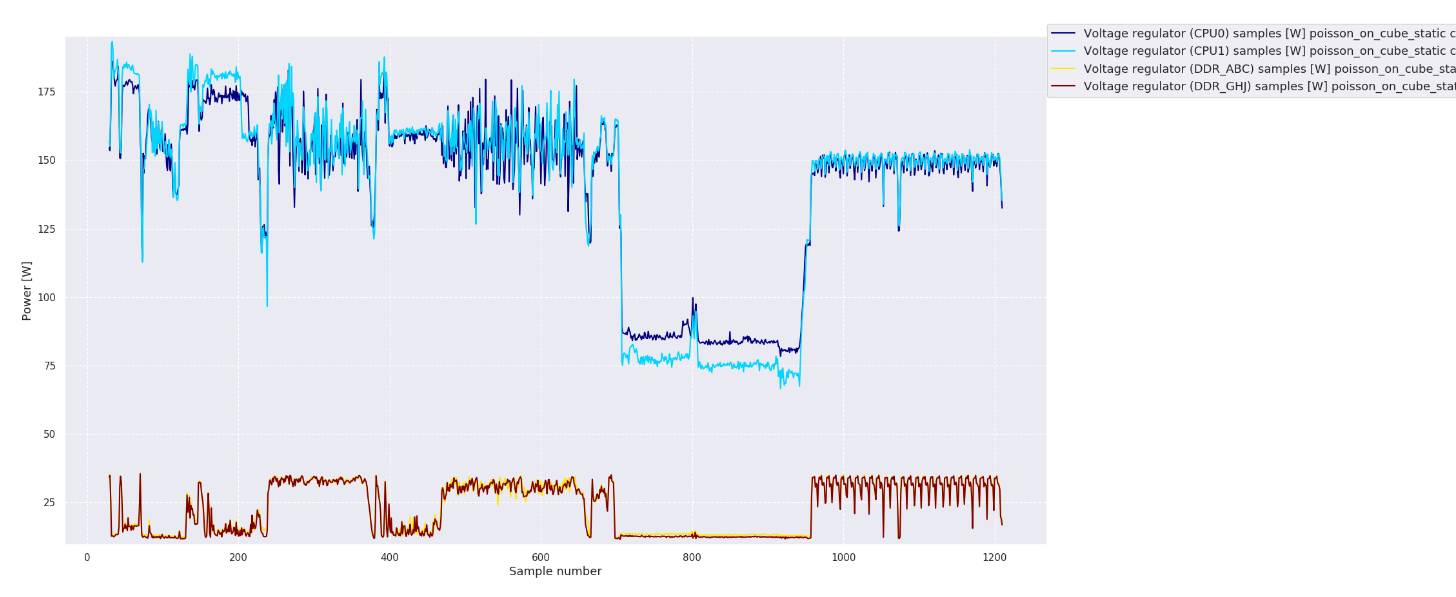
Fig. 2 Power consumption of blade components – two CPUs and two of four memory channels.
Energy savings
From the power consumption timelines, it is obvious that a single configuration of the frequencies, where they are constant during the application execution, is not as effective as dynamic tuning, leading to a performance penalty or limited energy savings. A static configuration of 1.9 GHz core and 1.9 GHz uncore frequencies provides the best compromise, extending the untuned 20.02 second run by about 830 milliseconds, while still bringing 25% energy savings.
Division of the application into smaller regions allows us to identify the configuration that best fits each part of the code. Regions that cover 63% percent of the runtime have the same optimal configuration as the optimal static configuration, while the remaining parts have different requirements. This dynamic tuning reduced the energy consumption by about 31%, with only a 140-millisecond runtime extension.
-- Ondřej Vysocký (IT4I)