ABINIT is a popular open-source materials science software suite to calculate observable properties of materials, starting from quantum equations of Density Functional Theory (DFT). It finds the total energy, charge density and electronic structure of systems made of electrons and nuclei using pseudopotentials and a planeware or wavelet basis. The Novel Materials Discovery Centre of Excellence NOMAD is readying ABINIT and three other codes as flagships for imminent exascale computer systems, and POP has been analysing them in its periodic assessment campaigns for HPC CoEs. While a GPU-enabled version of ABINIT is still under development, performance assessments of the MPI-parallelised Fortran code have been done on general-purpose dual 24-core Intel Xeon Platinum 8160 ‘Skylake’ compute nodes of MareNostrum4 supercomputer with Intel compilers and MPI & MKL libraries.
An initial assessment examined ground-state (SCF) calculations of a crystal comprising 107 gold atoms with a vacancy, comparing the performance of a newly incorporated RMM-DIIS solver using residual minimization method with direct inversion in the iterative subspace. It was determined to deliver superior performance and comparable scalability to the original solver, with strong scaling speedup of 39.2 from 1 to 40 compute nodes, despite requiring more SCF steps to converge.
For a follow-on assessment, the focus moved to a testcase studied within PRACE considered to be more challenging: a large-scale band structure calculation using the GW approximation (screening only) for an 11 atom Zr2Y2O7 dataset and converged parameters. This compound has a pyrochlore crystal structure with potential to be a promising catalyst for clean energy production and protection of the environment.
Pseudopotential description and associated eigenvalue and wavefunction data were prepared as input, with screening data for self-energy (sigma) calculation produced as output. NetCDF/HDF5 and Fortran file I/O are employed with MPI. While reading and distributing the large wavefunction data was a notable initialisation cost, it is negligible compared to the screening calculation. Writing of the screening data exclusively by the first process was also found to be insignificant.
With an MPI process bound to each physical processor core ABINIT screening calculations involved much more memory than available in MareNostrum4’s standard compute nodes (96 GB/node), necessitating use of “highmem” nodes. Memory usage of ABINIT is an ongoing investigation.
ABINIT screening calculations are performed sequentially for each wavevector, denoted q-point, and there are 36 of these for the testcase considered. Each q-point screening scans through associated electronic wavevectors (k-points), where shortcuts involving crystal symmetries can be employed (but were not possible for the studied testcase). The q0-point (0,0,0) includes extra commutator calculation (in cchi0q0) that screening the other 35 q-points does not, therefore the focus of analysis for the assessment was on the dominant cchi0 routine. Elapsed time for each cchi0 execution showed little variation within the screening calculation (and between measurements of the same calculation).
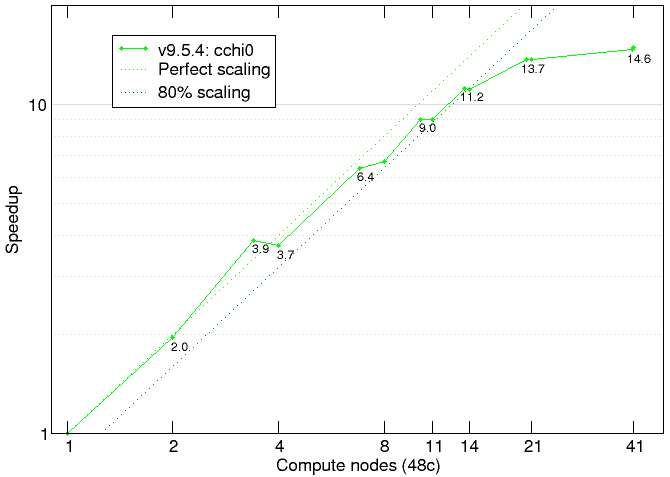
Figure 1: ABINIT testcase speedup on MareNostrum4
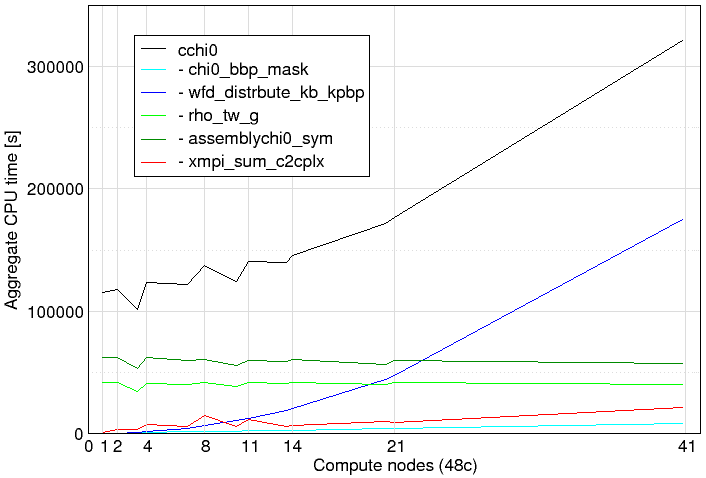
Figure 2: ABINIT testcase cchi0 scaling profile on MareNostrum4
Excellent strong scaling was found, with 11.2x speedup and 0.82 global scaling efficiency for 652 MPI processes (compared to the reference exeution with 48 MPI processes on a single compute node), but tailing off to 14.6x speedup (0.36 efficiency) for 1956 MPI processes. With only a single active (empty) band calculation per process, this was the ABINIT scaling limit of this testcase.
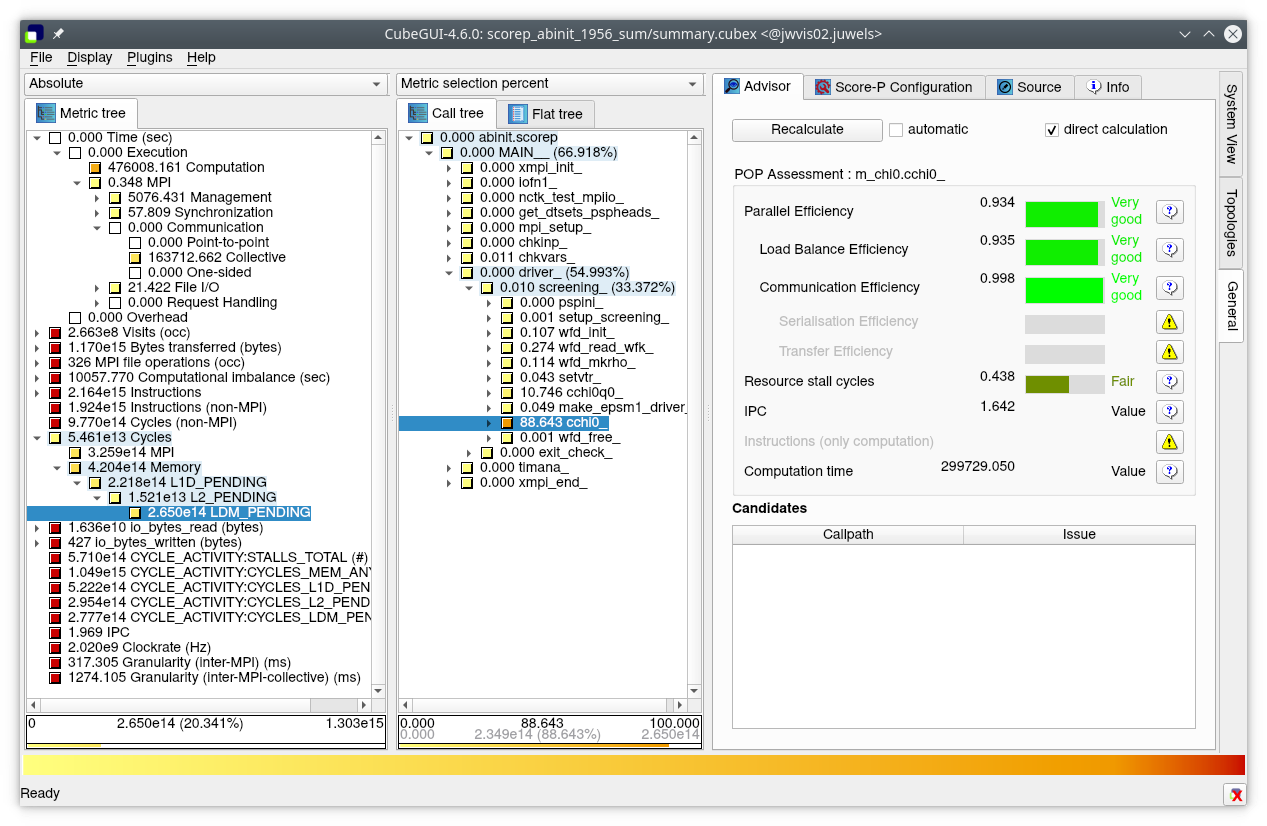
Figure 3: Summary analysis report of execution with 1956 MPI processes showing assessment of efficiency of cchi0 and its large memory access bottleneck producing severe execution stalls.
Load balance efficiency of 0.94 for this static decomposition remains very good, and communication efficiency is perfect with reductions only done at the end of each q-point calculation. The progressive degradation of global scaling efficiency derives predominantly from the poor computation time scaling (0.38 for 1956 processes): despite computation intensity (IPC) scaling of 3.24, instructions scaling has deteriorated to only 0.12 indicating rapidly growing excess computation. This was isolated to the (serial) wavefunction distribution routine that starts each q-point screening calculation, although it has very good IPC (2.3 for 1956 processes) and doesn’t use any floating-point operations. The routines that dominate executions with smaller numbers of processes scale well and exploit AVX512 16-way vector floating-point, but have very poor IPC. All executions are heavily memory access bound with more than 35% of (non-MPI) cycles attributable to pending loads from memory.
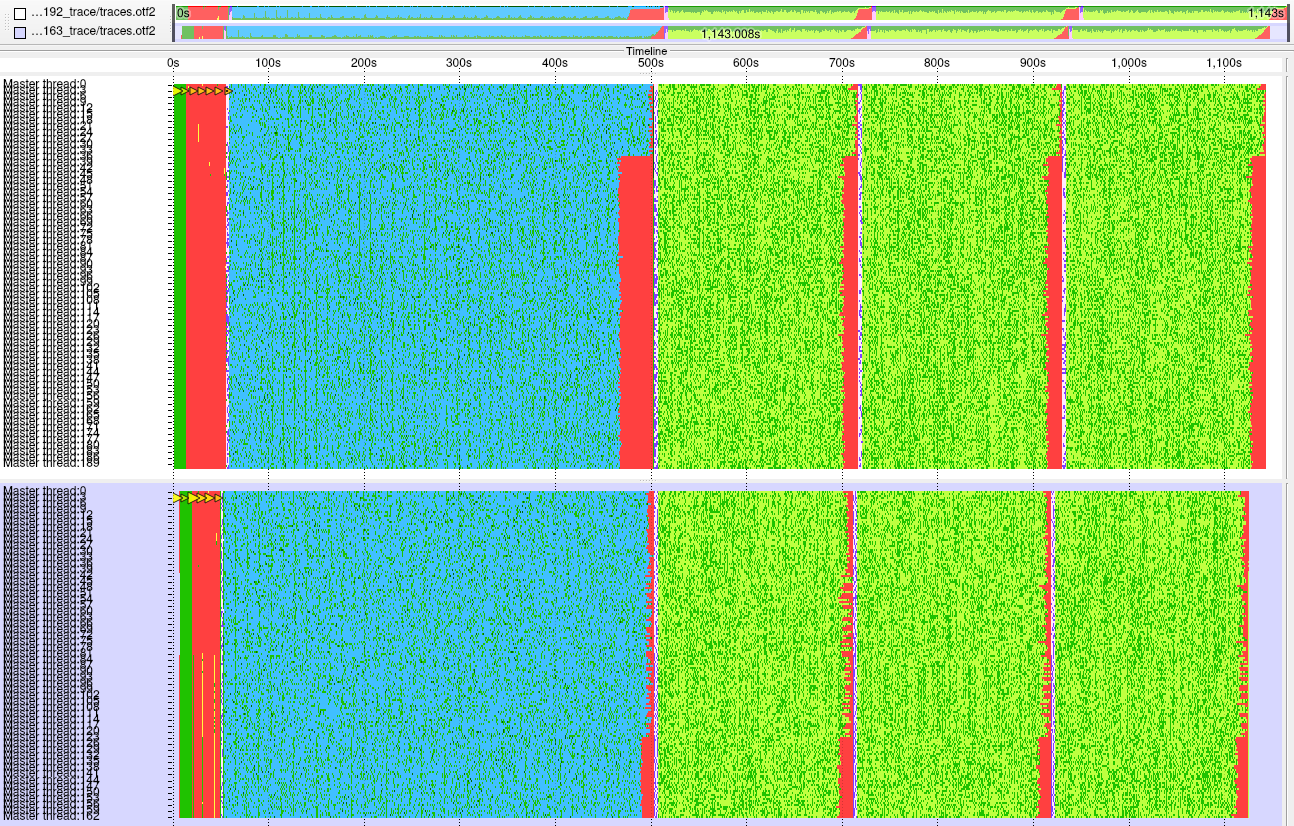
Figure 4: Timeline comparison of executions on 4 compute nodes with 192 and 163 MPI processes
ABINIT executions which exploit factors of the number of active (empty) bands, and don’t fully populate compute nodes with MPI processes, thereby deliver better performance. Using four compute nodes, executions with 163 processes (leaving 29 cores idle) are 4% faster than when fully-populated with 192 processes, delivering remarkable global scaling efficiency of 1.13! The memory bound nature of this ABINIT screening testcase also explained why its execution performance and scaling was found not to improve on the JUWELS Cluster module, which has more powerful Skylake processors with 25% faster CPU clockrate but the same DDR4-2667 DIMMs.
A couple of different approaches to exposing more parallelism and exploiting the much more efficient execution configurations with ensembles of fewer MPI processes have been identified as possible strategies for effective use of large current and imminent exascale computer systems by ABINIT, and these will be considered by the code developers in the remaining period of the NOMAD CoE.
-- Brian Wylie (JSC)