Alya, one of the reference codes of the EXCELLERAT CoE, is a high performance computational mechanics code to solve complex coupled multi-physics, multi-scale, multi-domain problems.
A POP performance assessment has been performed on an EXCELLERAT use case solved with Alya that simulates a Bunsen flame. The POP assessment unveiled that the main factor limiting scalability for this use case is the load imbalance. The load imbalance issue is inherent to the problem that is being solved, because the chemical reactions only happen and are thus computed in a small section of the domain. Moreover, where the chemical will happen cannot be computed beforehand, therefore the domain partition cannot be adjusted to minimize the imbalance.
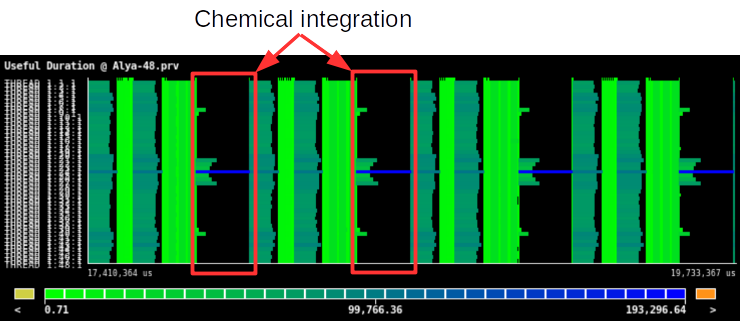
Fig 1: Trace showing the useful duration of 4 time steps of the bunsen flame using 48 MPI ranks.
In Figure 1, we show the useful duration of a trace with 48 MPI ranks of four steps of the bunsen flame use case. With the red squares we indicate the chemical integration phase, were we can see clearly the load imbalance. The proposal to address this issue from POP is to use the DLB library, as DLB is able to solve load imbalances that cannot be predicted beforehand and that can change during the execution. DLB uses the second level of parallelism (shared memory level) to solve the load imbalance at the MPI level. This is done spawning more threads to the more loaded processes when the less loaded processes reach a blocking MPI call.
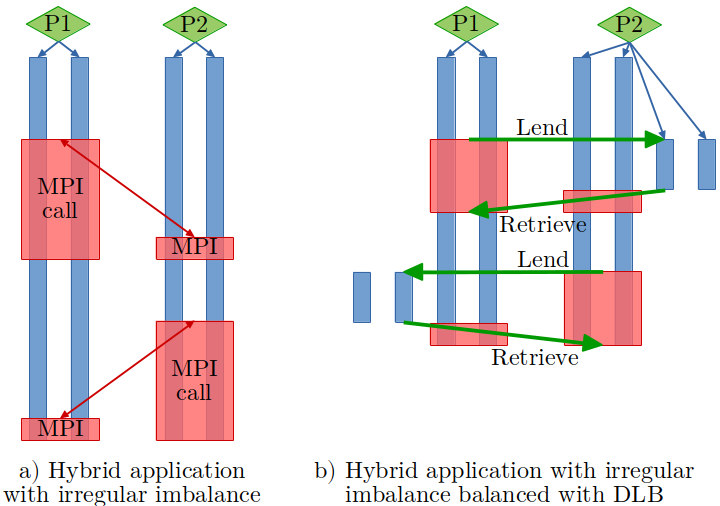
Fig 2: DLB example
In Figure 2, we can see an example of a hybrid application with load imbalance (left) launched with 2 MPI processes and 2 OpenMP threads each. In the right hand side, we can see the same application with DLB. We can observe when MPI process 1 reaches a blocking MPI call, it lends its threads to the MPI process 2. At this point MPI process to can use four threads to finish its computation.
The suggestion to use DLB to solve the load imbalance has been implemented within a POP proof-of-concept (PoC). In this PoC we have parallelized with a shared memory programming model the part of the code that suffers from load imbalance. Then, we can enable the load balancing with DLB by adding a call to the API.

Listing 1: Code modification. Left: Original code. Right: Modified code to enable DLB load balancing
In Listing 1, we can see the original code (left) and the modified code to enable load balancing with DLB. In blue, we show the code added to parallelize with OmpSs and in red the code necessary to enable DLB in this section of the code.
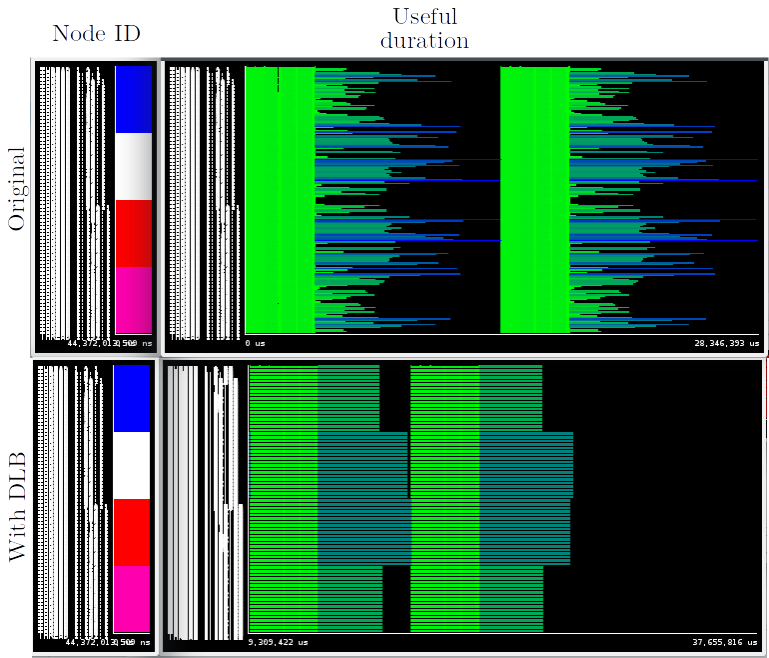
Fig 3: Traces without DLB (original) and with DLB of the Bunsen flame use case
Figure 3 shows two traces comparing the original execution (top) with 192 MPI processes and the same execution with DLB (bottom). We can observe how the DLB execution is able to load balance the MPI processes inside the same node, achieving almost a 2x speedup.
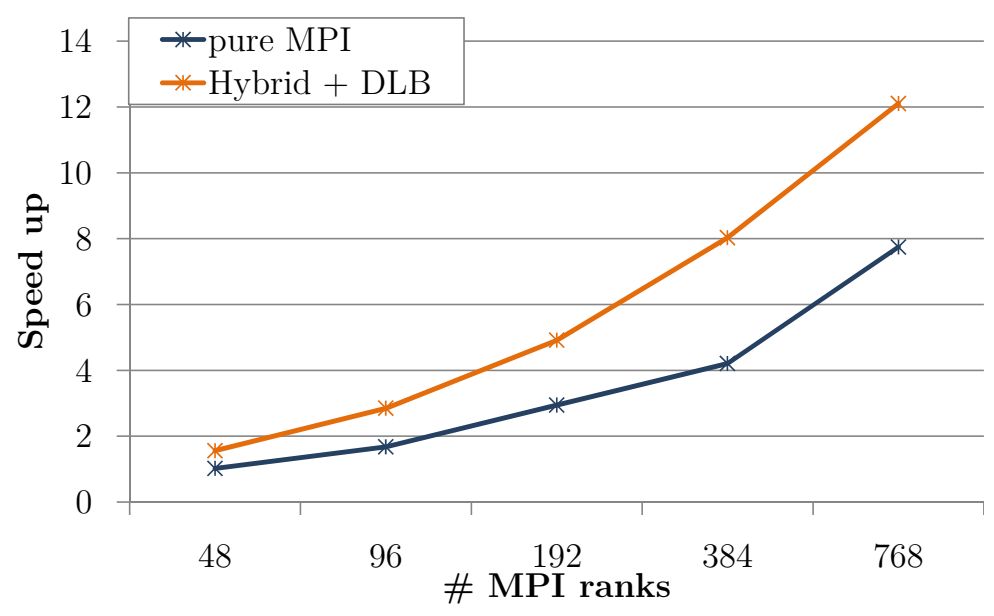
Fig 4: Speedup obtained with the original run and with DLB up to 768 MPI processes
Finally, we evaluate the performance obtained up to 768 MPI ranks (16 Marenostrum4 nodes). Figure 4 shows the speedup obtained with respect to the original run with 48 MPI ranks (1 Marenostrum4 node). We conclude that with DLB we obtain a speedup of 2x independently of the number of MPI processes up to 768 MPI ranks.
-- Marta Garcia (BSC)